






Below is a sample of the emails you can expect to receive when signed up to callas software.
|
To celebrate this new release as well as Cyber Monday, we will offer pdfToolbox Desktop for € 249,5 instead of € 499 (VAT excl.). The promotion starts on December 2 at 3 PM CET and ends on December 4 at 3 PM CET.
No Images? Click here 
Get pdfToolbox on Cyber Monday ... or Tuesday!Hello Oliver! Cyber Monday is coming up and that is not a regular Monday. It’s probably the one time a year you look forward to Monday mornings. On that day, we celebrate online shopping and that’s why we have a special offer in store for you … But more importantly: are you already familiar with pdfToolbox? This powerful PDF preflight and correction application is very easy to use and performs well if it comes to workflow tasks. In pdfToolbox Desktop, you can fix PDF problems manually during preflight, whereas in pdfToolbox Server you can do this fully automated! 
Recently, we released version 11 which is all about improvements to automated workflows and making PDF files production ready. Version 11 focuses on harnessing its powerful processing engines in automated workflows and adding functionality needed to complete such workflows.
More information
To celebrate this new release as well as Cyber Monday, we will offer pdfToolbox Desktop for € 249,5 instead of € 499 (VAT excl.). The promotion starts on December 2 at 3 PM CET and ends on December 4 at 3 PM CET. 
Reward yourself!How can you reward yourself? You will need to register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2019". And yes, you will be able to buy as many pdfToolbox Desktops as you want! Let the countdown begin!  Need an introduction?On Cyber Monday (December 2) at 4 PM CET, Michiel Van den Saffele (Application Specialist at Four Pees) will hold an English webinar to show you how you can check in pdfToolbox whether or not your PDF files are ready to be printed. Don’t miss out!
Webinar
Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
|||||||||
|
Tomorrow: Make your PDF files print ready with pdfToolbox!
No Images? Click here 
Ready for your first steps in pdfToolbox?Hello Oliver! As part of the Cyber Monday Promotion, we want to give you a quick overview of its functionality. In this webinar, we will talk about PDF quality control, correction, color management, imposition and more! Don't forget to register! 
On Cyber Monday (December 2) at 4 PM CET, Michiel Van den Saffele (Application Specialist at Four Pees) will hold an English webinar to show you how you can check in pdfToolbox whether or not your PDF files are ready to be printed. As usual, this webinar is free of charge!
Register now
See you at the webinar! Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No Monday blues today, because we offer you a Cyber Monday deal you can’t refuse: pdfToolbox Desktop for € 249,5 instead of € 499 (VAT excl.).
No Images? Click here 
It’s an ‘add to cart’ kind of day!Hello Oliver! No Monday blues today, because we offer you a Cyber Monday deal you can’t refuse: pdfToolbox Desktop for € 249,5 instead of € 499 (VAT excl.). Don’t forget that you can buy as many pdfToolbox Desktops as you want! In a nutshell

 Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2019". And yes, you will be able to buy as many pdfToolbox Desktops as you want!
Buy now
Need an introduction?Today at 4 PM CET, Michiel Van den Saffele (Application Specialist at Four Pees) will hold an English webinar to show you how you can check in pdfToolbox whether or not your PDF files are ready to be printed. Don’t miss out!
Webinar
Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
|||||||||
|
The worse part about online shopping is having to get up and get your credit card out your wallet. We feel you, but remember that you only have one day left to buy pdfToolbox Desktop at half-price!
No Images? Click here 
If you can’t stop thinking about it … Buy it!Hello Oliver! The worse part about online shopping is having to get up and get your credit card out your wallet. We feel you, but remember that you only have one day left to buy pdfToolbox Desktop at half-price! That’s right, the Cyber Monday promotion ends tomorrow at 3 PM CET.  Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2019". And yes, you will be able to buy as many pdfToolbox Desktops as you want! 
Buy now
Grab your chance before it is too late! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Unfortunately, all good things come to an end: you only have 6 hours left to buy pdfToolbox Desktop at half-price! That’s right, the Cyber Monday promotion ends today at 3 PM CET.
No Images? Click here 
Nothing haunts us more like the things we didn’t buyHello Oliver! Unfortunately, all good things come to an end: you only have 6 hours left to buy pdfToolbox Desktop at half-price! That’s right, the Cyber Monday promotion ends today at 3 PM CET.  Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2019". And yes, you will be able to buy as many pdfToolbox Desktops as you want! 
Buy now
Better safe than sorry! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
On January 9 at 4 PM CET, David van Driessche (CTO of Four Pees) will hold an English webinar to show you around in pdfToolbox 11.
No Images? Click here 
Ready to be a pdfToolbox 11 expert?Hello Oliver Over the years, callas software added many powerful processing engines to pdfToolbox. Version 11 focuses on harnessing those engines in automated workflows and adding functionality needed to complete such workflows. pdfToolbox is increasingly used in complex automated workflows, where files need to be handled from quality control all the way to delivery for production. Our goal with version 11 was to make such automated workflows easier to implement. Join our webinar(s)!On January 9 at 4 PM CET, David van Driessche (CTO of Four Pees) will hold an English webinar to show you around in pdfToolbox 11. The new version is all about improvements to automated workflows and making PDF files production ready. Don’t miss out!
Register now
There is also a German webinar, held by callas software, on that same day at 10:30 AM CET. Have a look! Can't wait?At the VIP Event in Riga, we presented pdfToolbox 11 in all its glory! We dedicated eight sessions which covered most of the new features and improvements of this new version. Have a look! 



More videos
Lust for more? Subscribe to our YouTube channel and don’t forget to ring the bell if you want to get notifications every time we publish a new video! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2019 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Note that we are out of office on Christmas (December 25, 2019) and New Year's Day (January 1, 2020).
No images? Click here 

Always jingle all the way, that's our motto! Hello Oliver! Always jingle all the way, that's our motto! That’s only possible thanks to your ongoing contribution – in one way or another. Therefore, we are really thankful! Note that we are out of office on Christmas (December 25, 2019) and New Year's Day (January 1, 2020). Furthermore, we are entirely at your disposal during the festive season! Happy Holidays from everyone at Four Pees! 🎄 Products | Training | Solutions | Support | Events | Company 
© 2019 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
On January 9, we will hold an English webinar to show you around in pdfToolbox 11!
No images? Click here 
Curious for pdfToolbox 11?Hello Oliver! Over the years, callas software added many powerful processing engines to pdfToolbox. Version 11 focuses on harnessing those engines in automated workflows and adding functionality needed to complete such workflows. pdfToolbox is increasingly used in complex automated workflows, where files need to be handled from quality control all the way to delivery for production. Our goal with version 11 was to make such automated workflows easier to implement. 
Join our webinar(s)!On January 9 at 4 PM CET, David van Driessche (CTO of Four Pees) will hold an English webinar to show you around in pdfToolbox 11. The new version is all about improvements to automated workflows and making PDF files production ready. Don’t miss out!
Register now
There is also a German webinar, held by callas software, on that same day at 10:30 AM CET. Have a look! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
callas software is organizing another PDF Camp in 2020. The focus of this year's event will be on how the new versions of pdfToolbox and pdfaPilot can be used in practice.
No images? Click here 
PDF Camp, organized by callas software, shows the potential of automation Berlin, January 29, 2020 – callas software, a leading provider of automated PDF quality assurance and archiving solutions, is organizing another PDF Camp in 2020. The focus of this year's event will be on how the new versions of pdfToolbox and pdfaPilot can be used in practice. Both software products contain a wide range of new features for automating PDF processing within complex workflows. The PDF Camp will be held on March 30-31, 2020 at the Pfefferwerk in Berlin. The event is aimed at both users of callas software products and interested parties with general questions about PDF. callas software recently released pdfToolbox 11 and pdfaPilot 9. Both versions offer a wide range of new options that allow users to automate their workflows. At the PDF Camp, attendees will be able to try out these sometimes complex features under real-world conditions and develop concrete solutions to their individual challenges. "The PDF Camp is the best opportunity to get concrete answers to PDF-related questions, and to get to know the potential applications for our solutions to the challenges and questions that surround PDF-based processes", says Dietrich von Seggern, Managing Director at callas software, adding: "The plenum will determine which challenges to focus on at the start of the event. Participants will then be divided into small groups to develop suitable solutions. Our developers, product managers and directors will provide support throughout." 
Tickets to the PDF Camp will cost € 199 (VAT excl.). Customers with a maintenance contract and callas partners will only pay € 99 (VAT excl.). Registration is now open:
Registration
Over callas softwarecallas software finds simple ways to handle complex PDF challenges. As a technology innovator, callas software develops and markets PDF technology for publishing, print production, document exchange and document archiving. callas software helps agencies, publishing companies and printers to meet the challenges they face by providing software to preflight, correct and repurpose PDF files for print production and electronic publishing. Businesses and government agencies all over the world rely on callas software’s future-proof, fully PDF/A compliant archiving products. In addition, callas software technology is available as a programming library (SDK) for developers with a need for PDF optimization, validation and correction. Software vendors such as Adobe®, Quark®, Xerox® and many others have recognized the quality and flexibility provided by these callas tools and have incorporated them into their solutions. callas software actively supports international standards and has been participating in DIN, ISO, CIP4, the European Color Initiative, the PDF Association, BITKOM and the Ghent Workgroup. callas software is a founding member of the PDF Association and has been involved in the board of the international association from the very beginning. callas software is based in Berlin, Germany. For more information, visit the callas software website at: www.callassoftware.com. Press contactFour Pees Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe
Preferences | Unsubscribe
|
|
We start the new decennium with a new PDF Camp! This year, the main focus will be on the practical use of the new versions of pdfToolbox and pdfaPilot.
No images? Click here 
Let us show you the potential of automation at PDF Camp! Hello Oliver! We start the new decennium with a new PDF Camp! As usual, the event will be held in the hometown of callas software: Berlin. This year, the main focus will be on the practical use of the new versions of pdfToolbox and pdfaPilot. Both software products contain a wide range of new features for automating PDF processing within complex workflows. So, make sure you mark March 30-31, 2020 in your calendar!
Get your ticket

For those who are not familiar with the PDF Camp: it's a technical and hands-on event where we work in groups to find answers to your PDF questions. The idea is that you bring up your production problems and project challenges, so don't forget to bring your own laptop. When registering for the event, please add your preferred subjects! Based on your requests, we will address different topics in hands-on groups. The topics might be related to any of our products or to a more general PDF topic. The event language will be English, but we all speak several languages and we will do our best to accommodate attendees that do not feel comfortable speaking English, e.g. by organizing German, Dutch or French speaking groups. A ticket for PDF Camp costs € 199 (VAT excl.). Are you a SMA customer or a callas partner? Then you get 50% discount and will only pay € 99 (VAT excl.). So, get your ticket before it is sold out! See you in Berlin! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Tomorrow, we will hold an English webinar to show you around in pdfToolbox 11!
No images? Click here 
Don't forget to register for our upcoming pdfToolbox 11 webinar!Hello Oliver! Tomorrow at 4 PM CET, David van Driessche (CTO of Four Pees) will hold an English webinar to show you around in pdfToolbox 11. The new version is all about improvements to automated workflows and making PDF files production ready. Don’t miss out!
Register now
There is also a German webinar, held by callas software, on that same day at 10:30 AM CET. Have a look! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Starting the new year off at full speed, callas software has released version 9 of pdfaPilot. The centerpiece of this update is the fully reworked editor used to create and modify process plans.
No images? Click here 
pdfaPilot 9 leads the way to automation New workflow editor and additional features make it easier to create and manage complex processes Berlin, January 24, 2020 – Starting the new year off at full speed, callas software has released version 9 of pdfaPilot. The centerpiece of this update is the fully reworked editor used to create and modify process plans, which now has a graphical interface. With this tool, users can create even complex workflows more easily than ever - further automating their PDF-based processes. pdfaPilot 9 also contains a number of new features which offer users more flexibility in how they process PDF files. "More and more customers are using pdfaPilot as part of complex workflows, processing their PDF files differently depending on various criteria", said Dietrich von Seggern, Managing Director at callas software, adding: "For version 9, we therefore integrated the features users need to further automate their processes." 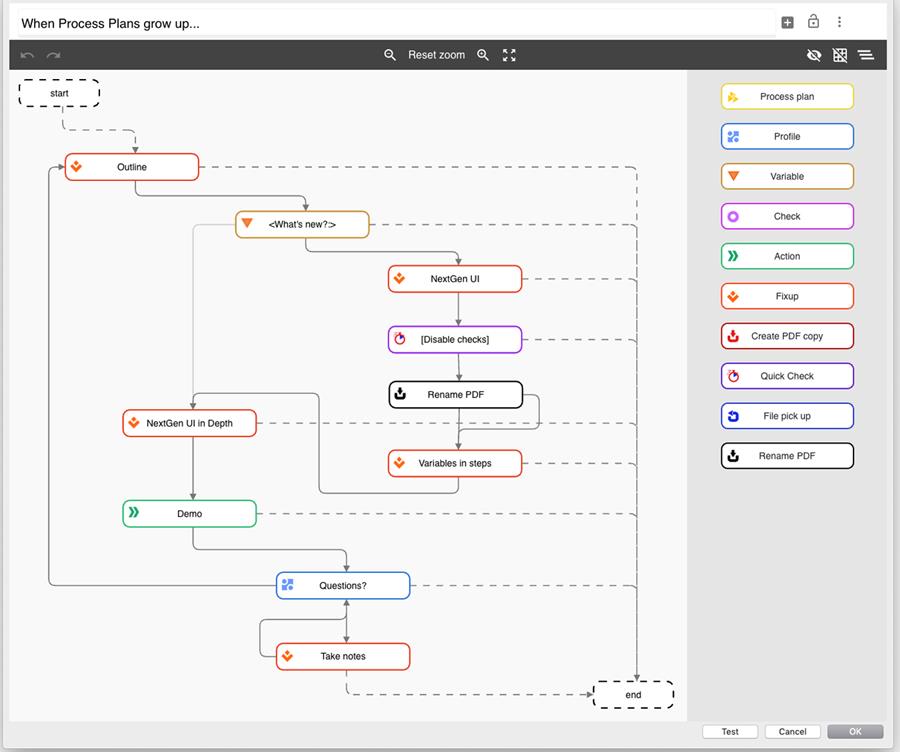
Graphical workflow editorOne key new feature of pdfaPilot 9 is the workflow editor, which makes even complex processes easier to implement. The graphical interface shows users a range of self-explanatory symbols, which they can then drag and drop to visually design process plans. Typical use cases for these kinds of processes include automatically editing, adding to or validating PDF files. They can be designed to incorporate user interaction, like entering variables and personalized ask-at-runtime dialogs. More flexibility when processing hot foldersIn general, pdfaPilot Server will automatically process all files saved to hot folders in line with the parameters associated with the server job. callas software has expanded this functionality for version 9, making hot folders more flexible and adding a 'job ticket' mode. Job tickets are control files where all parameters for processing PDF files can be defined. They can also optionally contain a link to the PDF files for pdfaPilot to process. Additional featurespdfaPilot 9 also contains a number of new features which are particularly well suited to process automation. For example, it can read barcodes and QR codes, using the extracted values to direct the rest of the workflow. pdfaPilot can also optionally use text markings to determine where to split PDF files. This feature is useful for dividing up print spool files, for example when producing invoices. Another option in pdfaPilot 9 is to trigger actions whenever certain content is found within a PDF file. About callas softwarecallas software finds simple ways to handle complex PDF challenges. As a technology innovator, callas software develops and markets PDF technology for publishing, print production, document exchange and document archiving. callas software helps agencies, publishing companies and printers to meet the challenges they face by providing software to preflight, correct and repurpose PDF files for print production and electronic publishing. Businesses and government agencies all over the world rely on callas software’s future-proof, fully PDF/A compliant archiving products. In addition, callas software technology is available as a programming library (SDK) for developers with a need for PDF optimization, validation and correction. Software vendors such as Adobe®, Quark®, Xerox® and many others have recognized the quality and flexibility provided by these callas tools and have incorporated them into their solutions. callas software actively supports international standards and has been participating in DIN, ISO, CIP4, the European Color Initiative, the PDF Association. BITKOM and the Ghent Workgroup. callas software is a founding member of the PDF Association and has been involved in the board of the international association from the very beginning. callas software is based in Berlin, Germany. For more information, visit the callas software website at: www.callassoftware.com. Press contactFour Pees Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Together with our UK & Ireland reseller Oris Packaging Innovations, we will exhibit at Packaging Innovations. You can find us at booth E13!
No images? Click here 


Increase the success of your product at Packaging Innovations! Hello Oliver! Packaging Innovations is UK's leading packaging event for the whole supply chain. This two-day event will take place on February 26 and 27, 2020 in the National Exhibition Centre of Birmingham (United Kingdom). 
Together with our UK & Ireland reseller Oris Packaging Innovations, we will exhibit at Packaging Innovations Birmingham. You can find us at booth E13! Our collaboration shows an interaction between hardware and software when it comes to packaging mockups and labels with workflow automation. We can't wait to show you our solutions that will tackle most of your packaging worries:
If you would like to get to know one of our solutions, you can book a product demo in advance:
Book a product demo
Packaging Innovations is free if you register in advance, so why hesitate to pay us a visit? See you in Birmingham! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
A huge thanks to all of you for believing in us and trusting us in helping you make better decisions/workflows. We are looking forward to the next decennium and what is has in store for PDF!
No images? Click here 
The time of the year where we look back, take stock & plan ahead Hello Oliver! We can all agree that 2019 was a crazy year: from the anticlimax in the Game of Thrones' finale to the launch of Tesla's Cybertruck which included a broken window mishap. In all this madness, there has been plenty of upsides as well - especially in callas' world. From the improved Process Plan UI to callas License Server, we ticked off everything on our to-do list for 2019. Have a look at our highlights! 
A huge thanks to all of you for believing in us and trusting us in helping you make better decisions/workflows. We are looking forward to the next decennium and what is has in store for PDF!
Read blog post
Happy New Year! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Together with our UK & Ireland reseller Oris Packaging Innovations, we will exhibit at Packaging Innovations. You can find us at booth E13!
No images? Click here 


Let's tackle your packaging worries at Packaging Innovations! Hello Oliver! Together with our UK & Ireland reseller Oris Packaging Innovations, we will exhibit at Packaging Innovations Birmingham. This event will take place on February 26 and 27, 2020 in the National Exhibition Centre of Birmingham (United Kingdom). Packaging Innovations is free to visit if you register in advance, so why hesitate to pay us a visit? 
You can find us at booth E13! If you would like to get to know one of our solutions, you can book a product demo in advance:
Book a product demo
We can't wait to show you our solutions that will tackle most of your packaging worries:
See you in Birmingham! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
pdfToolbox 12 launch: Hi Oliver, do you want to witness a lift-off?Hey Oliver! Always wanted to witness a lift-off? Well, today is your lucky day: pdfToolbox 12 will be launched soon and you can experience it front row! Launch:
Register here

If you want the new version but can’t wait to buy your pdfToolbox license(s), then we assure you that you can upgrade for free once it is officially released. Witness this jaw-dropping experience and register for our webinars:
Register here
Once registered, you will get a sneak peek of the new features in the agenda! At your service! Your callas team Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Time to gather your burning bleed-related questions! Hey Oliver! In our next Four Pees Café, we''ll talk about bleed:
This time, we will also have a special guest: Peter Kleinheider from calibrate Workflow-Consulting. He will assist us during this Café to answer all your burning bleed-related questions! 🔥 
Can you make it in time? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Use your (extra) time to gain more in-depth knowledge!Hey Oliver! During summer, time is usually on our side. Seize this opportunity with both hands and use your (extra) time to gain more in-depth knowledge! Did you know that we regularly shoot blog posts into the world? That''s right! We talk about PDF, its internals, demanding use cases, interesting solutions, discussions that we had during our events, how PDF should evolve and much more! You can even get an email whenever we release a new blog post, so you don''t miss out:
Subscribe to our blog
We have included an overview of our most recent blog posts. In that way, you are up-to-date in one go: RPA-based office workflows, using PDF
The RPA (Robotic Process Automation) approach is similar to the automated process that is common in manufacturing companies, where robots are working in factories and taking over the assembly of systems, machines or vehicles. Do you think that RPA applications would be a more common sight in back offices in the coming years? Discover our view on the matter in the following blog post!
Read more
Regulate counterfeits with label printing
Product piracy is something that strikes fear into the heart of many brand owners. How can printers of packaging and labels help their customers to fight counterfeits? Well, Amazon has invented the ‘Transparency’ service to fight off counterfeiting, which has in turn opened new doors of realm for packaging and labelling industry. Let’s understand how Transparency works and learn what it could mean for the packaging and labelling industry in our new blog post!
Read more
Managing manufacturing information with PDF
In the manufacturing industry, the importance of 3D data has recently grown. In light of this, the PDF Association - along with the 3D PDF Consortium - has recently published a high-level introduction about the roles and capabilities of PDF technology in manufacturing industries. With the availability of the necessary technology for the visualization of such 3D data, this technology is used to avoid loss of information in production, scholarly publishing, in situ publishing of 3D figures and much more! Check callas’ view on the matter in this blog post!
Read more
What can Robotic Process Automation (RPA) learn from prepress?
The IT industry has embarked on a new topic: Robotic Process Automation. RPA covers the automation of processes by eliminating manual activities to a large extent, so software solutions can take over. With today''s processor speed and increasingly sophisticated algorithms in software applications, IT can now carry out increasingly complex requirements faster and, for recurring tasks, more reliable than any human being. The RPA model originated in industrial production. Robots carry out the work in the manufacturing industry, and humans are only there to control and monitor the processes. In order to function smoothly, the processes and also the materials to be processed must be standardized as much as possible, which usually is the case in manufacturing processes, but not necessarily in office processes … As RPA will most likely be pushed by the current crisis, we would like to have a look at RPA from a PDF point of view!
Read more
Lust for more? Then you should definitely have a good browse through our blog! Stay healthy! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
| No images? Click here | |||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||
|
No images? Click here 
If you can’t stop thinking about it … Buy it!Hello Oliver! The worse part about online shopping is having to get up and get your credit card out your wallet. We feel you, but remember that you only have one day left to buy pdfToolbox Desktop at half-price! That’s right, the Cyber Monday promotion ends tomorrow at 3 PM CET.  Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2020". And yes, you will be able to buy as many pdfToolbox Desktops as you want! 
Buy now
Grab your chance before it is too late! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
How PDFs make implementing RPA applications easier Berlin, August 25, 2020 – The subject of Robotic Process Automation (RPA) is gaining increasing attention in the software industry. An increasing number of providers from a diverse range of sectors are introducing applications that can complete tasks previously handled by humans. By adopting these applications, users expect to benefit from optimizing their processes, avoiding errors and eliminating monotonous, repetitive tasks. Dietrich von Seggern, Managing Director at callas software GmbH, explains why the PDF format forms a sound basis for RPA applications. 
In order for RPA applications to work smoothly, processes must both have a standard structure and work with standardized files. This is the only way to maximize the number of files processed by a single automation. In many cases, this means that RPA can only work with data that it has itself generated. But why not use a standard here too? There are many good reasons to use the PDF format whenever such processes need to interact with third-party data. After all, PDF is the lowest common denominator for nearly all document types processed or received in offices. Office files, emails and even images can be easily converted to PDF, giving RPA applications a standardized starting point for processing. Moreover, with the many features it has accumulated over the years, PDF is the most powerful, versatile document format in the world. However, not every PDF meets the prerequisites for automatic processing equally well. This starts not with a reliable display model for the document, but rather the actual data it contains. Making PDFs RPA-ready
ConclusionBusinesses looking to maximize process automation can and should first establish a framework for seamlessly leveraging RPA-based applications. Part of this is about building a solid foundation, using maximally homogeneous, standardized data. As the highest common factor for Office files, high-quality PDFs are a good starting point for this foundation. About callas softwarecallas software finds simple ways to handle complex PDF challenges. As a technology innovator, callas software develops and markets PDF technology for publishing, print production, document exchange and document archiving. callas software helps agencies, publishing companies and printers to meet the challenges they face by providing software to preflight, correct and repurpose PDF files for print production and electronic publishing. Businesses and government agencies all over the world rely on callas software’s future-proof, fully PDF/A compliant archiving products. In addition, callas software technology is available as a programming library (SDK) for developers with a need for PDF optimization, validation and correction. Software vendors such as Adobe®, Quark®, Xerox® and many others have recognized the quality and flexibility provided by these callas tools and have incorporated them into their solutions. callas software actively supports international standards and has been participating in DIN, ISO, CIP4, the European Color Initiative, the PDF Association. BITKOM and the Ghent Workgroup. callas software is a founding member of the PDF Association and has been involved in the board of the international association from the very beginning. callas software is based in Berlin, Germany. For more information, visit the callas software website at: www.callassoftware.com. Press contactFour Pees Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about color, and more specifically Extended Color Gamut workflows! Hey Oliver! During our next Four Pees Café, we will talk about color, and more specifically Extended Color Gamut workflows using the ColorLogic tools. Our special guest will be Dietmar Fuchs from ColorLogic! 👏 As usual, you can bring any questions you have (about ColorLogic or color in general) to the Café! ☕ 
Can you make it in time? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
Have you already marked the PDF Camp in your calendar? The event will be held on March 30-31, 2020 in Pfefferwerk (Berlin).
No images? Click here 
Take a closer look at pdfToolbox 11 & pdfaPilot 9 during the PDF Camp! Hello Oliver! Have you already marked the PDF Camp in your calendar? The event will be held on March 30-31, 2020 in Pfefferwerk (Berlin). This year, the main focus will be on the practical use of the new versions of pdfToolbox and pdfaPilot. Both software products contain a wide range of new features for automating PDF processing within complex workflows.
Get your ticket

What can you expect? For those who are not familiar with the PDF Camp: it''s a technical and hands-on event where we work in groups to find answers to your PDF questions. The idea is that you bring up your production problems and project challenges, so don''t forget to bring your own laptop. When registering for the event, please add your preferred subjects! Based on your requests, we will address different topics in hands-on groups. The topics might be related to any of our products or to a more general PDF topic. The event language will be English, but we all speak several languages and we will do our best to accommodate attendees that do not feel comfortable speaking English, e.g. by organizing German, Dutch or French speaking groups. A ticket for PDF Camp costs € 199 (VAT excl.). Are you a SMA customer or a callas partner? Then you get 50% discount and will only pay € 99 (VAT excl.). So, get your ticket before it is sold out! See you in Berlin! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about how PrimeCenter creates ready-for-production files! Hey Oliver! In our upcoming Café, we will have a closer look at Caldera’s newly released PrimeCenter. This tool can help you reduce manual prepress actions and provide nested, ganged and preflighted documents that can be sent directly to the RIP. Besides the main nesting feature, it also includes other known Caldera prepress tools and an embedded version of callas pdfToolbox. These combined technologies create a powerful tool that offers a great level of automation for large format printing shops. 
Can you make it in time on July 7? 🇺🇸 Los Angeles, United States: 07:00 AM
Join us
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Doubtful about Zoom? Then we suggest you read the article ''Video service Zoom taking security seriously''. Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Break an egg! Hey Oliver! Next Monday, the hunt is on for Easter eggs. So, don''t forget we will be out of office on April 13. We are already egg-cited! No worries, we will be back in the office on Tuesday April 14. Break an egg! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Let us inspire you with our blog!Hello Oliver! At callas software, we want to use our business experience and passion to inspire you. That''s why we regularly shoot blog posts into the world. We talk about PDF, its internals, demanding use cases, interesting solutions, discussions that we had during our events, how PDF should evolve and much more! Do you suffer from FOMO (or Fear of Missing Out)? Subscribe to our blog! In that way, you''ll get an email whenever we release a new blog post. Don''t miss out!
Subscribe
Need to catch up?We have included an overview of our most recent blog posts. In that way, you''re up-to-date in one go! Spotify in pdfToolbox - all about spot colors
Why would you convert an image that only uses spot colors to PDF, while maintaining the original appearance of the image as closely as possible? Let''s figure out how Spotify can help you in your workflows in the following blog post:
Read more
The time of the year where we look back, take stock & plan ahead
Looking back over the past year, there has been plenty of upsides in callas'' world. From the improved Process Plan UI to License Server, we ticked off everything on our to-do list for 2019. Ready for the first blog post of the decennium?
Read more
Digital publication of regulations and laws in Brandenburg (Germany)
Did you know that the German state Brandenburg started to publish all laws digitally since 2009, and used PDF for that? In this blog post, we are happy to explain the requirements you would need for that:
Read more
Automating complex workflows with pdfToolbox 11!
pdfToolbox 11 brings many new capabilities for workflow automation – and makes creation of complex automation Profiles a lot nicer via a brand-new Process Plan editor! As you can see, we have a lot to talk about in this blog post:
Read more
VIP Event in Riga - All about preflight, automation & pdfToolbox 11
We, along with axaio software and Four Pees, wrapped up our annual VIP Event in Riga. More than 50 stakeholders attended this event that focused on the theme ''pdfToolbox 11''. Missed it? Read more in this blog post about what happened at the VIP Event:
Read more
Lust for more? Then you should definitely have a good browse through our blog! At your service! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Let''s talk about new PDF standards & PDF-based business processes at PDF Days Europe! Hello Oliver! On April 27-28, the entire PDF industry will gather at the PDF Days Europe in Berlin to celebrate the diversity of PDF applications and solutions. Come to learn what other companies are achieving by leveraging PDF technology! 
As a Gold Sponsor, we can give you € 100 discount on your ticket. Simply use our promotion code ''PDF-2020-Promo-Callas1'' on the registration page:
Get your ticket
What''s on the agenda?As a technology innovator, callas software will take care of two presentations: PDF/A-4, PDF/R-1 and other new PDF standardsTogether with Rene Rebe from ExactCODE GmbH, Dietrich von Seggern (Managing Director at callas software) will introduce you to the revision of PDF 2.0 which comes with a whole series of related standards. PDF/A-4 introduces various changes in features and structure of conformance levels. PDF/R-1 is completely new and modernizes raster image data transfer, especially in the mobile and cloud age. We will also amplify on the new standards PDF/X-6 and PDF/VT-3. In addition, ISO used this opportunity to harmonize all these standards, so it will be more straightforward for a PDF to comply with more than just one standard. More information A graphical workflow editor for business process modelingTogether with Michael Karbe from Actino Software GmbH, Dietrich von Seggern (Managing Director at callas software) will show you how to develop and design PDF-based business processes using a brand new graphical workflow editor, that can then used for process automation. More information The PDF Days Europe will be immediately followed by a Post-Conference workshop day on April 29. This day will offer a variety of practical workshops around PDF - both in English and German.
Agenda
See you in Berlin! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Four Pees announces its intent to integrate the activities of agileStreamsChristian Blaise becomes Director of Professional Services & SupportGhent/Chessy 22 October 2020 - Four Pees, international distributor and integrator of products and solutions to streamline print and packaging production, announces its intent to integrate the activities of agileStreams, French integrator of solutions for the graphics industry. As a part of this collaboration, Christian Blaise, CEO of agileStreams, will join Four Pees as Director of Support & Professional Services. 
In this role, he will focus on further expanding and structuring the automation services of Four Pees. This acquisition is a next step in Four Pees’ strategy to expand its service offering and geographic reach in order to better serve its customers and further establish itself as the reference international independent software integrator specialized for the print industry. Four Pees and agileStreams share the same vision to help print operations succeed by implementing hassle free automation. The current health crisis has further confirmed the need for implementing lean production techniques in the various sub segments of print industry. Printers and print related operations need a knowledgeable, responsive, sizeable and reliable partner to assist them with that. In addition to its role as a specialized software distributor, Four Pees has increasingly been providing complete solutions to customers. From web-to-print over packaging prototyping, job onboarding, color management, online collaboration/approval, automated proofreading to media and ink optimization, Four Pees is enabling them to better streamline their production. These services are offered both directly to end customers and in collaboration with existing resellers and partners. Over the past few years agileStreams has built itself an excellent reputation offering consultancy and implementation services to reference customers like Ubisoft, Glénat, Le Monde, L’Oréal and others. Through the integration in Four Pees, agileStreams customers will benefit from the same expertise and an expanded products and services offering and a larger team. Tom Peire, CEO at Four Pees: “The integration of agileStreams fits perfectly in the position that Four Pees finds itself in and our ambition to further grow. Having known and worked with Christian as colleague, customer and partner in the past I know that he can take our support and professional services team to the next level. In addition, it will help us expand our presence and increase our service level in the French market. We are excited to have Christian on board” Christian Blaise has more than 30 years of experience in the graphics industry, working for various international companies such as Nestlé, Enfocus and Gap Systems. The last 14 years he has implemented automation and process optimization at print and packaging companies. In addition, Christian has been active in the Ghent Workgroup for over 16 years where he is Co-Chair of the Packaging Sub-Committee and Marketing Officer. Christian Blaise, CEO at agileStreams: “Tom and I share a common view in how our industry has been evolving and how digitization and automation has influenced the print production workflows in the various companies we work with, whether those are commercial, banner & sign or packaging printers but also brand owners such as consumer goods and pharmaceutical companies. We share the vision around a pragmatic and project-based approach of automation in these companies. We are therefore convinced that this collaboration can only benefit our clients. I look forward building this success together.” About Four PeesReimagine your print production. Not just as a way of making your work easier, but as a way of thriving your print organisation. At Four Pees, we help print operations succeed by implementing hassle-free automation. We provide solutions to streamline the entire print and packaging production. Whether it is with advice, a software product or a seamlessly integrated solution from ideation, design and customization all the way up to fully automated production. Four Pees is the exclusive worldwide distributor of the callas software product ranges, the most complete PDF processing solutions. Other brands represented by Four Pees are
Aleyant, axaio software, Caldera, CMA Imaging, ColorLogic, Creative Edge Software, CtrlSoftware, Elpical, Global Vision, InSoft, Laidback Solutions, Remote Director and treeDiM. For more information: www.fourpees.com Press contact Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 


Coming up: no manic Monday, but Whit Monday! Hello Oliver! No manic Monday next week, because we have a bank holiday coming up: Whit Monday. So, don''t forget we will be out of office on June 1. No worries, we will be back in the office on Tuesday June 2! Have a nice (long) weekend! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about approval, using the Switch Review Module Hey Oliver! In Enfocus Switch, you can include approval steps into an automated workflow using the Review Module. This makes it easy to send out e-mails to people with a link to the file that needs to be approved. ✔️ In tomorrow''s Café, we will not only show you this technique, but also an alternative using a database and a way to do double approval (in case a file for example needs to be approved both by the creative and the legal department). 
Can you make it in time on April 17? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
 | ? |
|
On 11 Mar 2020, at 14:55, Andy Banks <andy.banks@fourpees.com> wrote:Hi Oliver, and hope you are well....
You downloaded a trial of Callas pdfToolbox from our website and I thought I would take this opportunity to introduce myself to you as the UK & Ireland Technical Sales Manager at FourPees, and to find out how it went/is going and also better understand what interest you initially had in the solution and if pdfToolbox met with your expectations?
Quite often with any software trial, fully understanding what the benefits are and how you can use it to your advantage can be a task to get your head around so I have included two links below to maybe help and assist you...
The first link is to a Step by step - Learn how to use callas pdfToolbox...
A really useful resource that we put together with callas to help guide users with the functions within pdfToolbox...
https://help.callassoftware.com/m/pdftoolbox
The second link is from a webinar we presented - Features in pdfToolbox by David van Driessche (FourPees CTO)...
https://www.youtube.com/watch?v=YNrxP53UmXc
The latest v.11 released early this year was one of the most feature rich updates Callas has ever done with the product with a big change to how process plans can be put together and also huge leaps forward with extended bleed creation technology, to name just two!...
Please feel free to contact me anytime if you have any further questions about pdfToolbox or anything else regarding automation, workflow and reducing manual and repetitive tasks and I'm also more than happy to schedule a remote session via TeamViewer or GoToMeeting to help assist you and answer any questions you might have...
FourPees have a broad offering of workflow automation software with solutions other than pdfToolbox that are used widely across all areas of the printing industry, and would also be more than happy to discuss any of these if it was of interest to you also...
I'd love to hear back from you and learn more about what you do...
Best Regards...
Andy Banks - FourPees NV
? ?
?
Andy Banks | Technical Sales Manager UK ? P +44 20 3868 3465? | M +44 7919 574543? |www.fourpees.com ? Need support? ?
?
|
No images? Click here 


Tomorrow we will have our head in the clouds! Hello Oliver! Tomorrow is Ascension Day, and that''s a bank holiday in Belgium. So, don''t forget we will be out of office on May 21, 2020. No worries, we will be back in the office on Friday May 22! Kind regards Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Never get bored with our new YouTube playlists! Hi Oliver! Did you know that we already have 89 videos on our YouTube channel? That''s a lot of knowledge! To organize those videos and bring order into the chaos, we have made 10 very obvious playlists - good for hours of viewing pleasure!

More playlists
Psst ... If you don''t want to miss out: subscribe to our YouTube channel and ring the bell if you want to get notifications every time we publish a new video! 📬
Subscribe to our YouTube channel
Enjoy! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about custom PDF reports in pdfToolbox! Hey Oliver! Join our next Café to understand custom PDF reports in pdfToolbox. pdfToolbox can create multiple preflight reports that can help prepress people or customers understand what is wrong with their PDF document. One of those reports is a fully customizable PDF report based on a HTML template. During the Café, we wil look at where you can find examples, how they can be integrated into pdfToolbox, how you can modify them ... 
Can you make it in time on June 3? 🇺🇸 Los Angeles, United States: 07:00 AM ⚠️ Don''t forget you need to register in advance! Once registered, you will receive a confirmation e-mail with instructions to join us.
Register here
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Doubtful about Zoom? Then we suggest you read the article ''Video service Zoom taking security seriously''. Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
PDF Days Europe is cancelled! Hello Oliver! The PDF Association has decided to cancel PDF Days Europe: "As much as we were looking forward to the event, the coronavirus has led us to conclude that the event is no longer feasible in April. There is a good chance that related dynamics, such as media, public reactions, travel restrictions and the possibility of force majeure decisions by respective governments, will eventually put a stop to the event." We recommend to immediately cancel your airline tickets and hotel accommodation. There might a possibility that the PDF Days Europe will be rescheduled later this year, but this needs to be evaluated once the full impact is clear. So, we suggest you keep an eye on your mailbox! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
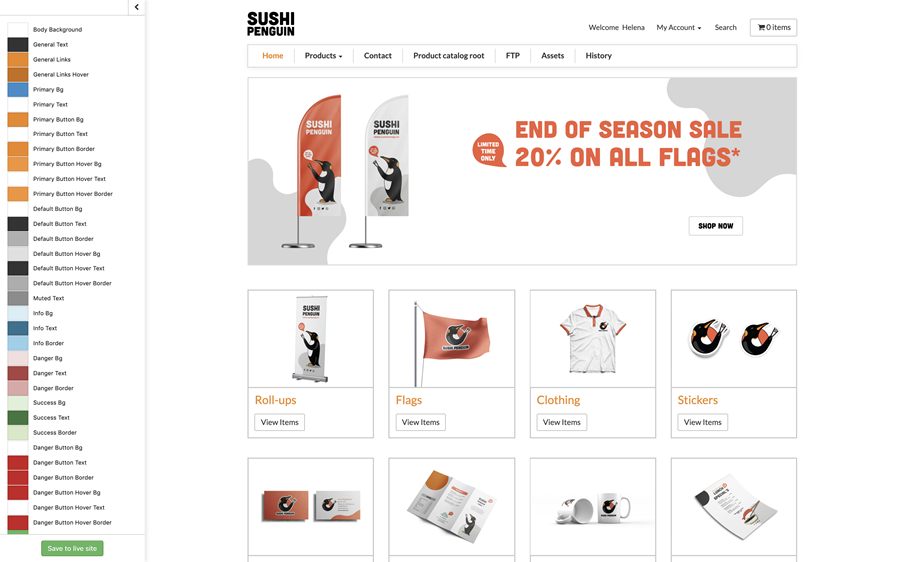
Time to get your web shop up and running! Hello Oliver! Chances are that your customers will use it a lot right now, and then you would better be prepared! Pressero is a cloud-based B2C or B2B storefront for printers, especially developed for the print industry. Creating your own online open or closed storefront really becomes child’s play as it requires little to no knowledge of web technology. That doesn’t mean you can’t fully adapt your storefront to your branding. 
What you see, is what you get!In the web-to-print platform of Aleyant Pressero, you have various skin options. A skin is a basic design layout for your web shop. Each skin has different areas that are available to change/edit with custom images, colors, options ... To help you customize these skins, there’s also the Live Palette Editor. This feature helps to take the guess work out of the process and save you time. In the following video, we’ll briefly show you all of this. Have a look! 
Request an online demo
At your service! PS: Subscribe to our YouTube channel and don’t forget to ring the bell if you want to get notifications every time we publish a new video! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
brandbox creates web- and print-ready PDF files from a single source with callas technologyBerlin, June 30, 2020 – Users of Konmedia GmbH’s brandbox can now automatically process PDF files using pdfToolbox from callas software. brandbox is a universal marketing instrument which enables product communication across multiple media channels. Since this kind of use case introduces a number of challenges when it comes to creating PDF files, Konmedia decided to add the functionality of callas pdfToolbox to its brandbox software. This allows users to create PDF files for the respective application purposes from the same database without wasting time. 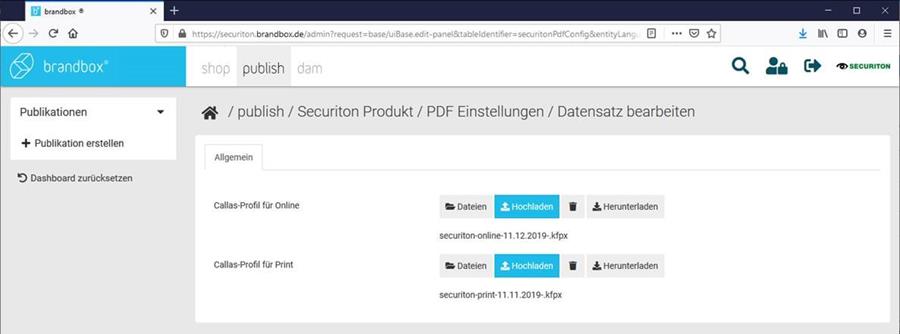
brandbox allows businesses to optimize their product communication by using databases to record and structure their catalogs and price lists. Its template engine then creates PDF files at the click of a button that are ready for immediate multichannel publication online and/or printing. "We have already integrated pdfToolbox on the server side for a wide range of conversion processes for printing", said Christoph Schmidt, Managing Director at Konmedia GmbH. "Since switching to the open-source system Kubernetes, we have relied entirely on callas’ technology." He added: "This has the benefit of allowing us to incorporate profiles for both online PDF publication and printing into brandbox." Wide range of configuration options when creating high-quality PDF filesWeb-to-print functionality is a cornerstone of brandbox’s services and solutions. "PDF documents that are made available for download online, for example, need to meet different requirements than those for printing", said Dietrich von Seggern, Managing Director at callas software GmbH. "pdfToolbox helps with both cases, since you can create profiles for each use case, giving users the results they need while still using the same source data." Users can either select tried-and-tested default web and print profiles, or they can define their own profiles individually. They can prepare, test and update these profiles anytime using a desktop application. This makes it possible to meet all publishing-specific requirements, of which there can be as many as several hundred. brandbox users also benefit from a number of additional pdfToolbox features, including:
Flexible licensing modelKonmedia uses pdfToolbox with callas’ License Server model. This dynamic billing model enables capacity-based processing and allows the company to distribute the processing load across multiple cloud-based instances. As a result, Konmedia can respond flexibly to demand and order more units if required. Given its positive experiences with catalog production to date, Konmedia is planning to also integrate pdfToolbox into its marketing portal with web-to-print editors in brandbox. These will generate PDFs one page at a time, after which they can be checked using the preflight engine. About callas softwarecallas software finds simple ways to handle complex PDF challenges. As a technology innovator, callas software develops and markets PDF technology for publishing, print production, document exchange and document archiving. callas software helps agencies, publishing companies and printers to meet the challenges they face by providing software to preflight, correct and repurpose PDF files for print production and electronic publishing. Businesses and government agencies all over the world rely on callas software’s future-proof, fully PDF/A compliant archiving products. In addition, callas software technology is available as a programming library (SDK) for developers with a need for PDF optimization, validation and correction. Software vendors such as Adobe®, Quark®, Xerox® and many others have recognized the quality and flexibility provided by these callas tools and have incorporated them into their solutions. callas software actively supports international standards and has been participating in ISO, CIP4, the European Color Initiative, the PDF/A Competence Center and the Ghent PDF Workgroup. In addition, callas software is a founding member of the PDF/A Competence Center and in October 2010, Olaf Drümmer became its chairman. callas software is based in Berlin, Germany. For more information, visit the callas software website at: www.callassoftware.com. Press contactFour Pees Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
It’s an ‘add to cart’ kind of day!Hello Oliver! No Monday blues today, because we offer you a Cyber Monday deal you can’t refuse: pdfToolbox Desktop for € 250 instead of € 500 (VAT excl.). Don’t forget that you can buy as many pdfToolbox Desktops as you want! In a nutshell

 Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2020". And yes, you will be able to buy as many pdfToolbox Desktops as you want!
Buy now
Kind regards, Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about using variables in pdfToolbox in a real-world context! Hey Oliver! This week, we will show you two approaches to use variables in pdfToolbox in a real-world context.
Use your (extra) time to gain more in-depth knowledge about pdfToolbox and join our cosy get-together! 
Can you make it in time on May 12? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Doubtful about Zoom? Then we suggest you read the article ''Video service Zoom taking security seriously''. Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

An Introduction to JavaScript - Session 1 Hey Oliver! So what do you do if you are not a developer or you have no knowledge of JavaScript? Joining this series will give you JavaScript fundamentals to build on and at the very least will make you more comfortable around the language and the supporting tools. Main reason for this of course is the increasing importance of JavaScript in the tools all of us in Graphic Arts tend to be using. It''s available in pdfToolbox, in Enfocus Switch (in two variants now), in the Adobe Creative Suite applications... 
Can you make it in time? 🇺🇸 Los Angeles, United States: 07:00 AM
Register
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Doubtful about Zoom? Then we suggest you read the article ''Video service Zoom taking security seriously''. Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Nothing haunts us more like the things we didn’t buyHello Oliver! Unfortunately, all good things come to an end: you only have 6 hours left to buy pdfToolbox Desktop at half-price! That’s right, the Cyber Monday promotion ends today at 3 PM CET.  Reward yourself!Just register on our webshop, add pdfToolbox Desktop to your cart and use the promotion code you received from your favorite reseller or our promotion code "FP-CYBER-2020". And yes, you will be able to buy as many pdfToolbox Desktops as you want! 
Buy now
Better safe than sorry! Kind regards Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Introduction to ColorLogic''s smart color server ZePrA 8 Hey Oliver! In our next Café, Dietmar Fuchs, Product Manager at ColorLogic GmbH, will introduce you to the new version of the ZePrA 8 color server, which now also supports proofing as a workflow. He will elaborate the background to the support of proofing in the color server and show you how easy it is to work with! En passant, other new features in version 8 will be demonstrated. Use your (extra) time to gain more in-depth knowledge about ZePrA and join our after-work! 
Can you make it in time on May 15? 🇺🇸 Los Angeles, United States: 07:00 AM ⚠️ Our next Café requires advanced registration! Once you registered, you will receive a confirmation e-mail with instructions to join us. From this Café on, you will also need a password to enter: fpcafe.
Register here
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Doubtful about Zoom? Then we suggest you read the article ''Video service Zoom taking security seriously''. Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
Use your (extra) time to gain more in-depth knowledge!Hey Oliver! Time is on our side nowadays. Seize this opportunity with both hands and use your (extra) time to gain more in-depth knowledge! Did you know that we regularly shoot blog posts into the world? That''s right! We talk about PDF, its internals, demanding use cases, interesting solutions, discussions that we had during our events, how PDF should evolve and much more! You can even get an email whenever we release a new blog post, so you don''t miss out:
Subscribe to our blog
We have included an overview of our most recent blog posts. In that way, you are up-to-date in one go: callas Desktop products ''explore'' your PDFs
Imagine a scenario where you have copy-pasted some text from your PDF to another location and it comes out totally different from what you had copied. Now what? You would want to explore the text inside the PDF, wouldn’t you? Well, what are you waiting for? Let''s explore!
Read more
Mobile Magazines
More and more, magazines are available on tablets or other mobile platforms. Consequently, many new apps appear where subscribers have access to several hundred publications, such as AppleNews+, Keep In Mind, Readly and many more. The subscriber uses the respective app to view the magazine pages, but in many cases the internal format is actually PDF. In this blog post, we want to have a look at what is needed to turn a print-ready PDF into lightweight performant PDF pages.
Read more
Spotify in pdfToolbox - all about spot colors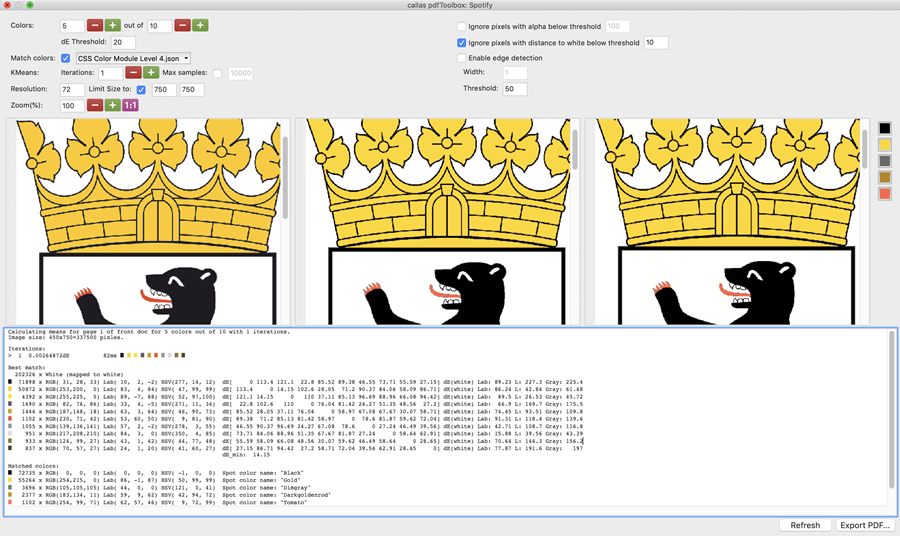
Why would you want to convert an image that only uses spot colors to PDF, while maintaining the original appearance of the image as closely as possible Let''s figure out how Spotify can help you in your workflows in this blog post!
Read more
The time of the year where we look back, take stock & plan ahead
Looking back over the past year, there has been plenty of upsides in callas'' world. From the improved Process Plan UI to License Server, we ticked off everything on our to-do list for 2019. Ready for the first blog post of the decennium?
Read more
Lust for more? Then you should definitely have a good browse through our blog! Stay healthy! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

We May take 1 day off! Hello Oliver! Tomorrow, we''re celebrating Labour Day. So, don''t forget we will be out of office on May 1, 2020. No worries, we will be back at your disposal on Monday May 4! Kind regards Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 


An ode to Belgian waffles, chocolate, beer ... Hi Oliver! Did you know that Belgian waffles have deeper pockets than other waffles? That makes them great for holding a lot chocolate spread, jam or syrup. Tomorrow, we pay tribute to Belgium, because it''s Belgian National Day! So, don''t forget we will be out of office on July 21. No worries, we will be back in the office on Wednesday July 22! Kind regards Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
On April 27-28, the entire PDF industry will gather at the PDF Days Europe in Berlin to learn about the latest trends in PDF and exchange ideas.
No images? Click here 
Celebrate the diversity of PDF applications and solutions at PDF Days Europe! Hello Oliver! On April 27-28, the entire PDF industry will gather at the PDF Days Europe in Berlin to learn about the latest trends in PDF and exchange ideas. The event will touch ''all dimensions of PDF'', as it performs as a critical workflow enabler, a multipurpose content vehicle as well as a powerful and broadly supported archival file-format. ISO-standardized PDF technology is indispensable across a vast range of document applications. We will celebrate the diversity of PDF applications and solutions by organizing interesting presentations given by leading companies. Come to learn what other companies are achieving by leveraging PDF technology! 
As a technology innovator, callas software will take care of two presentations: PDF/A-4, PDF/R-1 and other new PDF standardsTogether with Rene Rebe from ExactCODE GmbH, Dietrich von Seggern (Managing Director at callas software) will introduce you to the revision of PDF 2.0 which comes with a whole series of related standards. PDF/A-4 introduces various changes in features and structure of conformance levels. PDF/R-1 is completely new and modernizes raster image data transfer, especially in the mobile and cloud age. We will also amplify on the new standards PDF/X-6 and PDF/VT-3. In addition, ISO used this opportunity to harmonize all these standards, so it will be more straightforward for a PDF to comply with more than just one standard. More information A graphical workflow editor for business process modelingTogether with Michael Karbe from Actino Software GmbH, Dietrich von Seggern (Managing Director at callas software) will show you how to develop and design PDF-based business processes using a brand new graphical workflow editor, that can then used for process automation. More information The PDF Days Europe will be immediately followed by a Post-Conference workshop day on April 29. This day will offer a variety of practical workshops around PDF - both in English and German.
Agenda
As a Gold Sponsor, we can give you € 100 discount on your ticket. Simply use our promotion code ''PDF-2020-Promo-Callas1'' on the registration page:
Get your ticket
See you in Berlin! Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
 | ? |
|
|
Together with our UK & Ireland partner Oris Packaging Innovations, we will exhibit at Packaging Innovations. You can find us at booth E13, where we will show you how automation can take your production to the next level!
No images? Click here 


Automation takes your production to the next level! Hello Oliver! Together with our UK & Ireland partner Oris Packaging Innovations, we will exhibit at Packaging Innovations Birmingham. The event takes place on February 26 and 27, 2020 in the National Exhibition Centre of Birmingham (United Kingdom). You can find us at booth E13, where we will show you how automation can take your production to the next level! 
Book a product demo
We can''t wait to show you our solutions that will tackle most of your packaging worries:
Packaging Innovations is free to visit if you register in advance, so why hesitate to pay us a visit? See you in Birmingham! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about workflow, batching, ganging & imposition templates! Hey Oliver! In next week''s Four Pees Café, we will have a look at workflow, batching, ganging and imposition templates in Switch and pdfToolbox. This edition, we will be joined by two special guests from FunkyPigeon.com: John Symonds and Tom Skinner. They will elaborate on the demand and the critical importance of processing 10 000s of individual files a day. Their story will show you that error handling is vital! 📣 Spread the word and join us! 
Can you make it in time on April 21? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about JavaScript variables in pdfToolbox!! Hey Oliver! In a previous Café, we talked about simple variables in pdfToolbox. Did you know that pdfToolbox also supports JavaScript variables, which allow the whole system to be even more powerful? In our next Café, we''ll talk more about those, and how they can help you! 
Can you make it in time on April 24? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! If you don''t have a Facebook account, you can find all recordings here! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Let''s talk about bleed in PDF Files! Hey Oliver! In our next Four Pees Café, we will talk about bleed! How can you create bleed parameters for existing fixups? How can you create bleed for irregular shapes? What about the Detect and Create Bleed process plan in pdfToolbox 11? ... This time, we will also have a special guest: Peter Kleinheider from calibrate Workflow-Consulting. He will assist us during this Café to answer all your burning bleed-related questions! 🙋♂️ 
Can you make it in time? 🇺🇸 Los Angeles, United States: 07:00 AM
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 
pdfaPilot 9.1 supports ZUGFeRD 2.1 Berlin, May 26, 2020 – callas software, a leading provider of automated PDF quality assurance and archiving solutions, released an update for its pdfaPilot product line today. Aside from numerous smaller improvements, the standout feature for pdfaPilot 9.1 is its support for version 2.1 of the ZUGFeRD data model. The Forum for Electronic Invoicing Germany (FeRD) and the French National Forum for Electronic Invoicing and Public Digital Procurement (FNFE-MPE) recently published a joint e-invoicing standard in the form of ZUGFeRD 2.1 and Factur-X 1.0. With pdfaPilot 9.1, users can create, validate and process ZUGFeRD-compliant files that now also conform to version 2.1 of the e-invoicing data format. Since ZUGFeRD 2.1 is fully compatible with the French invoicing standard Factur-X 1.0, it will now be significantly easier for French and German providers to exchange e-invoices with one another. 
pdfaPilot 9.1 is available as an interactive desktop application, a hot-folder-based server application and an integration-ready command-line application and programming library. About callas softwarecallas software finds simple ways to handle complex PDF challenges. As a technology innovator, callas software develops and markets PDF technology for publishing, print production, document exchange and document archiving. callas software helps agencies, publishing companies and printers to meet the challenges they face by providing software to preflight, correct and repurpose PDF files for print production and electronic publishing. Businesses and government agencies all over the world rely on callas software’s future-proof, fully PDF/A compliant archiving products. In addition, callas software technology is available as a programming library (SDK) for developers with a need for PDF optimization, validation and correction. Software vendors such as Adobe®, Quark®, Xerox® and many others have recognized the quality and flexibility provided by these callas tools and have incorporated them into their solutions. callas software actively supports international standards and has been participating in ISO, CIP4, the European Color Initiative, the PDF/A Competence Center and the Ghent PDF Workgroup. In addition, callas software is a founding member of the PDF/A Competence Center and in October 2010, Olaf Drümmer became its chairman. callas software is based in Berlin, Germany. For more information, visit the callas software website at: www.callassoftware.com. Press contactFour Pees Products | Solutions | Develop | Support | Events | Company 
© 2020 callas software 
callas software products are distributed by Four Pees callas software GmbH
Schönhauser Allee 6/7 10119 Berlin Germany This communication is handled by Four Pees. You can read our privacy policy here: https://www.callassoftware.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
|
No images? Click here 

Ready to set up a web-to-print site in no time? Hey Oliver! In these surrealistic times, we all try to find opportunities. One of them might be your online presence! In order to survive this temporary lockdown and help out customers, it might be a good idea to set up a web-to-print site. Let''s see how quickly you can get a web-to-print site up and running with Aleyant Pressero! During this third Café, Helena will demonstrate you how to work with Pressero and make it obvious that you could literally be up and running with a functioning shop in a couple of days. 
Can you make it in time? 🇺🇸 Los Angeles, United States: 07:00 AM ❗Keep in mind that some countries are going over to daylight saving time!
Link to video call
Lust for more? Join our community where we post the recordings of previous hangouts and keep you informed of the next ones! Here''s to your health! Products | Training | Solutions | Support | Events | Company 
© 2020 Four Pees 
Kleemburg 1 - 9050 Gentbrugge - Belgium You can read our privacy policy here: https://www.fourpees.com/en/privacy-policy.
If you would like to change your e-mail preferences, simply click on Preferences. You will be able to manage your contact details, language and the products you would like to receive information on. If you no longer wish to receive any of our e-mails, simply click on Unsubscribe.
Preferences | Unsubscribe
|
| Data Name | Data Type | Options |
|---|---|---|
| This field cannot be left blank. Company | ||
| First name | ||
| Last name | ||
| Title | ||
| Password | ||
| City | ||
| State | ||
| Country | ||
| Zipcode | ||
| Mr | ||
| Mr |



 Press release
Press release



 Arts and Entertainment
Arts and Entertainment Business and Industry
Business and Industry Computer and Electronics
Computer and Electronics Games
Games Health
Health Internet and Telecom
Internet and Telecom Shopping
Shopping Sports
Sports Travel
Travel More
More