





Below is a sample of the emails you can expect to receive when signed up to Fast Forward Labs.
|

by Victor
Across many business use cases that generate data, it is frequently desirable to automatically identify data samples that deviate from �normal.� In many cases, these deviations are indicative of issues that need to be addressed. For example, an abnormally high cash withdrawal from a previously unseen location may be indicative of fraud. An abnormally high CPU temperature may be indicative of impending hardware failure.
The task of finding these anomalies is broadly referred to as Anomaly Detection, and many excellent approaches have been proposed (clustering-based approaches, nearest neighbors, density estimation, etc.). However, as data become high dimensional, with complex patterns, existing approaches (linear models which mostly focus on univariate data) can be unwieldy to apply. For such problems, deep learning can help.
In a recent post on Medium, I introduced Anomagram, an interactive visualization of how autoencoders can be applied to the task of anomaly detection. Anomagram is created as both a learning tool, and a prototype example of what an ML product interface could look like. The interface is built with Tensorflow.js and allows install-free experimentation in the browser.
The first part of the interface introduces important concepts (autoencoders, data transformations, thresholds, etc.) paired with appropriate interactive visualizations. The second part (pictured below) is geared towards more technical users and allows you to design, train, and evaluate an autoencoder model entirely in the browser.
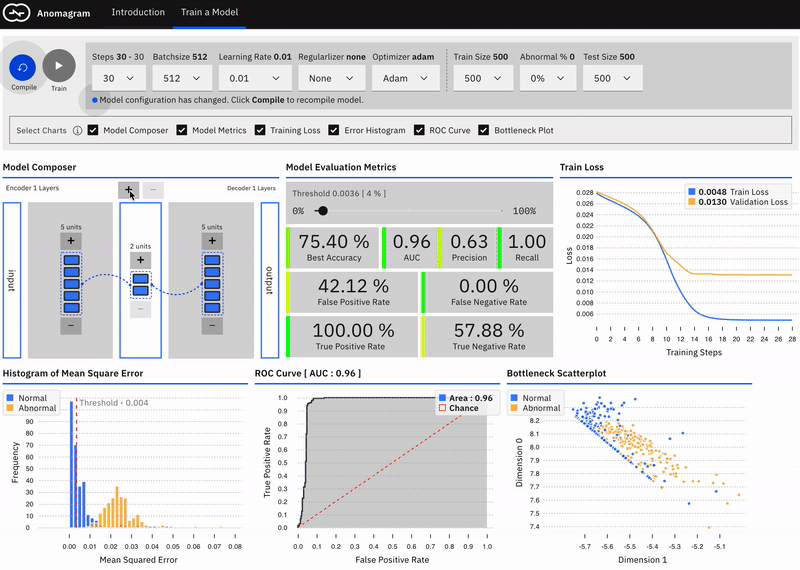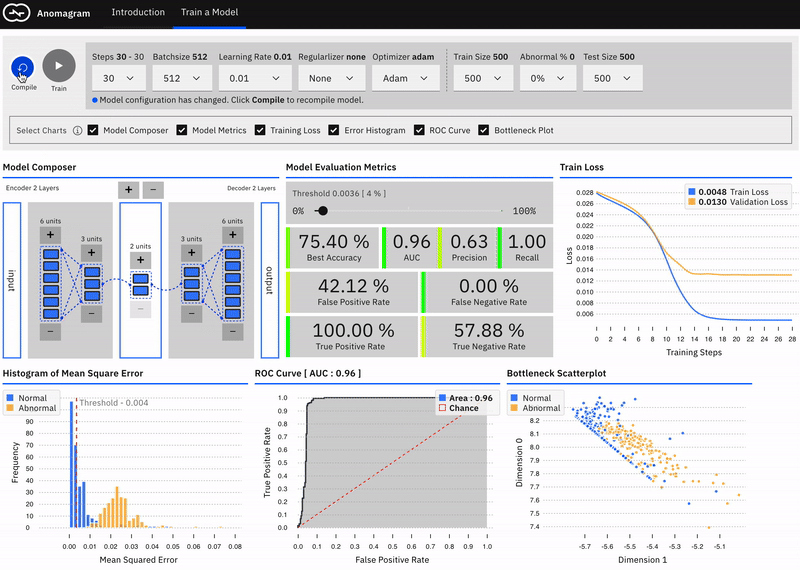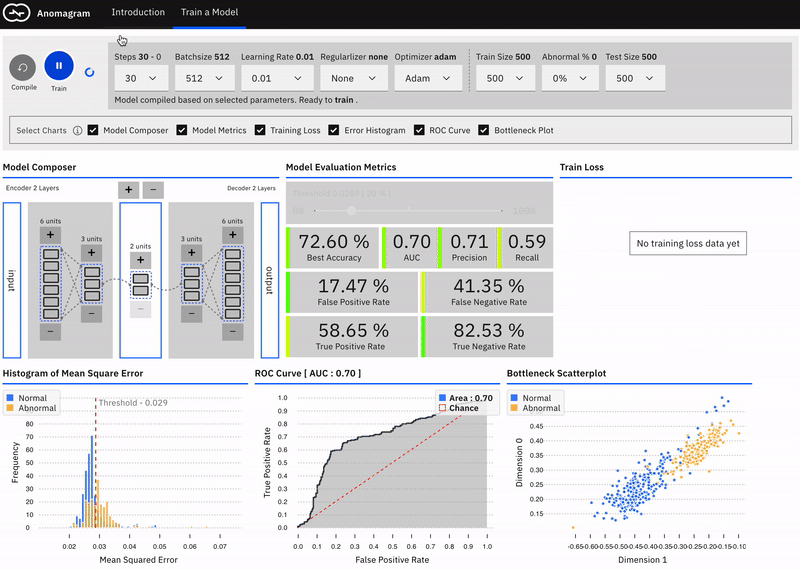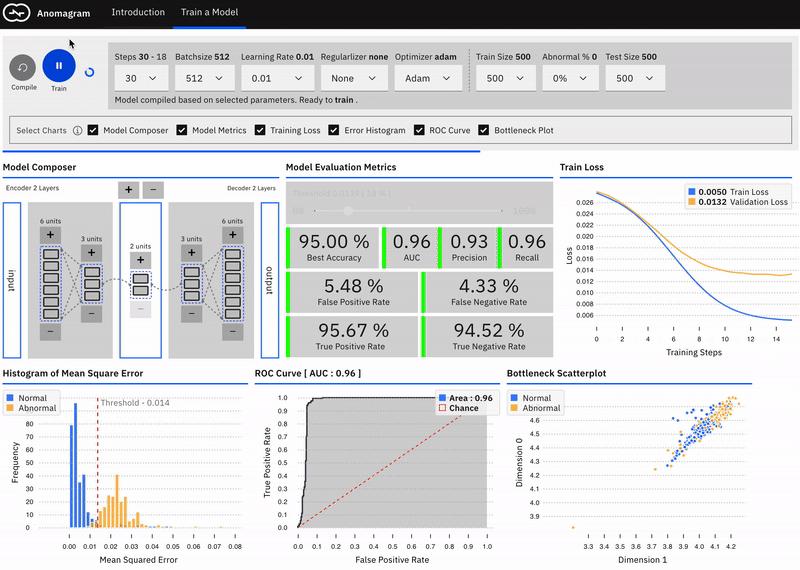
If you�re interested in learning more about other deep learning approaches to anomaly detection, my colleagues and I will cover additional details on this topic in our upcoming report on Deep Learning for Anomaly Detection. (Please join us for a webinar on this topic on February 13th at 10:00am PT!)
In the meantime, you can read my full article on Medium, view the full demo of Anomagram here, and find the project source code here.
by Andrew
For the past decade, humans have unknowingly come to depend on Knowledge Graphs on a daily basis. From personalized shopping recommendations to intelligent assistants and user-friendly search results, many of these accepted (and expected) features have come to fruition through the exploitation of knowledge graphs. Despite their longstanding conceptual and practical existence, knowledge graphs were just added to the Gartner Hype Cycle for Emerging Technologies in 2018 and have continued to garner attention as an area of active research and development for their distinct ability to represent real-world relationships.
In this article, we�ll take a high-level look at what knowledge graphs are and explore a few ways they interact with the field of machine learning.
With all the hype comes confusion. In its simplest form, a knowledge graph is a set of data points linked by relations that describe a real-world domain. A cursory Google search will result in a myriad of explanations, but I believe there are a few core concepts that characterize a knowledge graph implementation.
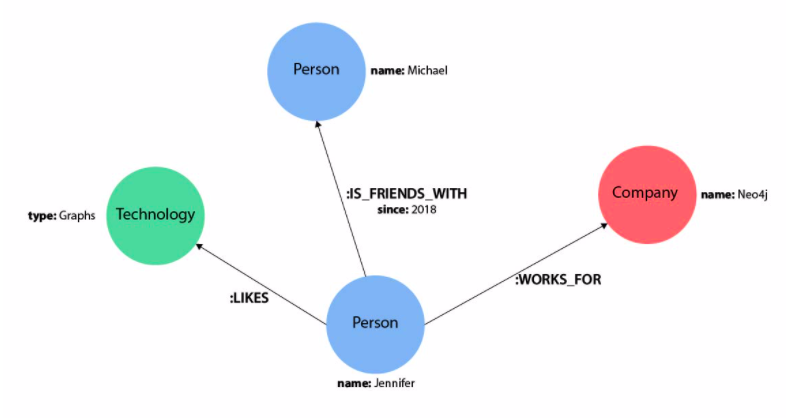
Image Credit
A concrete and relatable application of knowledge graph technology is demonstrated by Google�s Knowledge Graph which was launched in 2012 and has become a relied upon feature for all Google search users.
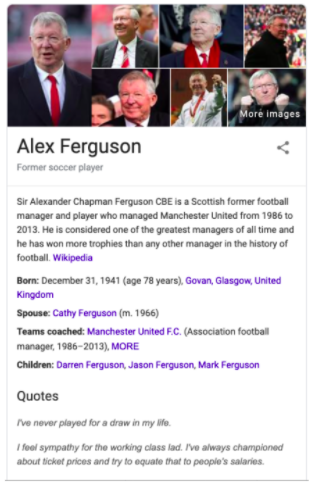
When searching for a specific person, Google provides users a side panel that contains relevant information surrounding the entity/subject in the query. This quick insight is made possible by Google�s Knowledge Graph - a pre-populated knowledge base of connected facts relating people, places, and things. Because the graph structure effectively represents this type of data by design, the facts seen above can be easily called upon to provide contextual insight.
Now that we have established a baseline intuition of what knowledge graphs are, let�s take a look at ways machine learning and knowledge graphs support each other.
Because knowledge graphs preserve relational information (and are therefore more complex than traditional data representations), the data they take in demands a more refined state. Specifically, the edges between nodes must be established and then wrangled into a complementary form before populating a graph.
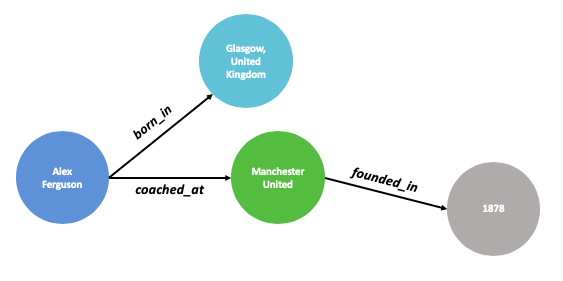
Let�s imagine a hand-crafted graph describing characteristics of Sir Alex Ferguson as seen above. Defining these entities and relationships is a simple endeavor for anyone knowledgeable of the English Premier League (EPL) and organizing the connections upfront allows the graph to be efficiently queried later on. But what happens if we want to create subgraphs for every manager in the EPL? Or every soccer manager in the world? Or every professional sports manager that ever existed?
Manually identifying all of these relationships by hand is not scalable. This is where machine learning and Natural Language Processing (NLP) offer intelligent solutions to automatically curate raw data into useable facts. The general techniques involved include sentence segmentation, part of speech tagging, dependency parsing, word sense disambiguation, entity extraction, entity resolution, and entity linking applied to corpuses of both structured and unstructured data.

The simplified example above is intended to highlight the general NLP process on a single sentence. In practice, organizations use more advanced, patented systems built on these underlying techniques to automatically extract information, resolve conflicting entities, and populate millions of entities into production knowledge graphs.
�Increasingly we�re learning that you can make better predictions about people by getting all the information from their friends and their friends� friends than you can from the information you have about the person themselves.�
? - James Fowler, Connected
The quote above poses a justified, but unconventional approach to predictive modeling. Traditional machine learning focuses on modeling tabular data that inherently cannot represent all of the cascading relationships found within networks and knowledge graphs. This often means data scientists are left trying to abstract, simplify, and even leave out predictive relationships baked into a knowledge graph�s structure. But what if features of every node in a knowledge graph could be derived from the context of all the nodes and edges around them?
There are few different methods for making use of connected features in machine learning, but a main area of attention is Knowledge Graph Embeddings (KGE). The goal of KGE�s is to learn a fixed vector space representation of any given node in a graph based on its nearby connections. Drawing a quick parallel to the Word2Vec algorithm (and concept of word embeddings) - where we learn a fixed vector representation for every word in a corpus based on nearby words - helps to frame the concept of KGEs. Specifically, the Node2Vec model expands upon ideas from Word2Vec by first randomly traversing subgraphs for each node in a network to build a large number of sequences [sentences]. Once we have a body of graph sequences [corpus], we can utilize Word2Vec methodology as it applies to text sequences to produce graph node embeddings.
Ultimately by learning embedding representations from the full context of a knowledge graph, we can extract deeply rich features to be used in downstream tasks. A few uses are:
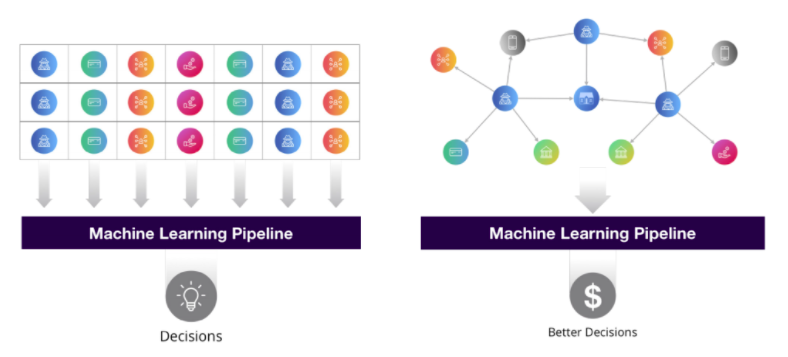
Image Credit
Knowledge graphs are an effective tool for modeling interconnected, real-world scenarios while retaining contextual details that are not easily captured with traditional data structures. In this article, we explored two examples that demonstrate the symbiotic relationship between knowledge graphs and machine learning, which only scratches the surface of the intersection between the two technologies. Additional concepts - like Graph Neural Networks and ML driven Entity Resolution - stand as exciting areas of research and application.
In keeping with our reputation as your data nerd friends, here�s a quick peek into what we�ve been reading lately:
This article from 2016 by our friend Ines at explosion.ai is still very much valid today. The role of front-end in data science is often restricted to visualization and dashboards. This is an enormous lost opportunity. It�s a personal resolution of mine to work more on interfaces for using and understanding machine learning systems in 2020. - Chris
This catalog of overfitting problems in ML models is both a pre-flight checklist for models, and a set of recipes to mitigate overfitting. It�s directed specifically to deep learning, but it�s applicable to other types of models as well. - Ryan
DRL shows promise for real world problems! Amazon applied DRL (via OpenAI Gym) to canonical operations research/supply chain problems such as bin packing, newsvendor and vehicle routing. They find that DRL beats or matches baseline. Next step - can this work for real world instances of these problems? (They think not yet). - Shioulin
This article questions the value of benchmark datasets for evaluating the true performance of NLP models. Some models may be exploiting shortcuts to obtain excellent scores while failing at the core of the task - in this case, reasoning and comprehension. - Victor
What may have started out as a bit of a joke actually highlights the importance of collaboration and respect within the open-source community towards the development of ML/AI products - characteristics that, as this article points out, are something Sesame Street fosters. One of my favorite excerpts from this article: �AI isn�t a discipline where lone scientists toil away in the lab at night, pumping electricity through processors, and cackling �It�s aliiiive� over a glowing command line. (Disclaimer: this certainly does happen, but it�s not always the most productive approach.)� - Danielle
Everest Pipkin provides a behind-the-scenes look at a creative coding class they recently taught. The assignments are all interesting and the student work looks great. I especially liked the �folder structure as memory palace� prompt. - Grant
Uber recently released a visual debugging tool for machine learning - Manifold. It is a model monitoring and debugging tool which compares feature distributions across tabular data subsets. It is model agnostic and helps users determine what data slices a model fails on and the potential causes for certain performance issues. It also integrates with Jupyter Notebook. It will be interesting to watch this space and how the features for the subsequent versions of Manifold unfold! - Nisha
A really interesting project from 2019 called code2seq introduced a method for generating natural language sequences from the structured representation of source code. This research sheds opportunity for automated code documentation and summarization. - Andrew
Brand new on arXiv this month, �Reformer: The Efficient Transformer� shows how old dogs can still learn new tricks. The authors reimplement the now-standard Transformer architecture (first brought to fame in the BERT NLP model) using Locality Sensitive Hashing, a long-standing tried-and-true technique for efficient look-up of similar items. This reduces the complexity of the algorithm and allows for longer sequences (e.g., sentences) to be used successfully. I love seeing classic techniques reinvented in modern algorithms! - Melanie
To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the July edition of Cloudera Fast Forward's monthly newsletter. This month, we have new research, new blog posts, new recommended reading, and we're very excited to invite you to our next research webinar tomorrow - Deep Learning for Automated Question Answering!
We're rounding out our blog series on Question Answering with these three recent posts.
Evaluating QA: the Retriever & the Full QA System
This post focuses on a vital component of a modern Information Retrieval-based (IR) QA system: the Retriever. Specifically, we introduce Elasticsearch as a powerful and efficient IR tool that can be used to scour through large corpora and retrieve relevant documents. We explain how to implement and evaluate a Retriever in the context of Question Answering and demonstrate its impact on an IR QA system.
How to Maximize Retriever Performance on a More Natural Dataset
Implementing question answering for real-world use cases is a bit more nuanced than evaluating system performance against a toy dataset. In this post, we explore several challenges faced by the Retriever when applying IR-QA to a more realistic dataset, as well as a few practical approaches for overcoming them.
Beyond SQuAD: How to Apply a Transformer QA Model to Your Data
Finally, we discuss how a Reader trained on SQuAD2.0 might perform on different datasets, particularly on highly specialized data - such as a collection of legal contracts, financial reports, or technical manuals. In this post we perform experiments designed to highlight how to adapt Transformer models to specialized domains and provide guidelines for practical applications.
If you're just catching up to our Question Answering series, check out the first three posts:
Intro to Automated Question Answering
Building a QA System with BERT on Wikipedia
Evaluating QA: Metrics, Predictions, and the Null Response
How to Explain HuggingFace BERT for Question Answering NLP Models with TF 2.0
Recently, our team at Fast Forward Labs have been exploring state of the art models for Question Answering and have used the rather excellent HuggingFace transformers library. As we applied BERT for QA models (BERTQA) to datasets outside of wikipedia (e.g legal documents), we have observed a variety of results. Naturally, one of the things we have been exploring are methods to better understand why the model provides certain responses, and especially when it fails. This post focuses on the following questions:
The post comes along with an interactive Colab notebook which you can try out! - Victor
Our research engineers share their favourite reads of the month.
Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead I recall this paper making a splash when it appeared in late 2018. I don't recall why I didn't read it at the time, and more fool me: it is a tour-de-force of constructive criticism. Cynthia Rudin draws a clear distinction between explainable and interpretable machine learning, and enumerates the challenges with each, and why we should prefer the latter. This is a must-read for anyone working on use cases that benefit from interpretability. - Chris
Dense Passage Retrieval for Open-Domain Question Answering
As we've learned through the FF14 blog series, open-domain question answering relies on efficient passage retrieval to first narrow large corpora of text into a handful of context passages for answer extraction. While traditional methods for passage retrieval rely on sparse vector models, this paper demonstrates how learned, dense representations for retrieval can help establish state-of-the-art performance on several end-to-end QA benchmarks. - Andrew
On Lacework by Everest Pipkin An artistic examination of a machine learning dataset and the assumptions and invisible labor that go into it. - Grant
Snorkel AI: Putting Data First in ML Development - We are excited to see this project that started in 2016 launch out of stealth! Snorkel AI enables machine learning practitioners to automate the data labeling process using an approach called weak supervision. Almost a year back we had a chance to tinker around with the library and also published a few blog posts. Things have much changed since then. The library has now evolved into Snorkel Flow - an end-to-end process of developing and deploying ML-powered applications by iteratively and programmatically labeling, augmenting, and building training data. - Nisha
Tempering Expectations for GPT-3 and OpenAI's API OpenAI recently released their GPT-3 API to beta users, and the accompanying paper Language Models are Few-Shot Learners. Reactions range from bored scepticism to skynet prophesying. This post from Max Woolf gives an informed take on what is a significant algorithmic and engineering advancement, but not magic. - Chris
Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping A must-read for any NLP practitioner! The authors perform a deep study into how fine-tuning language models (like BERT and XLNet) is a very brittle process. They demonstrate that, even with a fixed set of hyperparameters, results vary substantially due to the value of the random seed and even by the order of the training examples during training! They then offer practical guidance on how and when to stop training less promising models in favor of those more likely to converge, thus saving time and, ultimately, producing better models. - Melanie
Estimating Displaced Populations from Overhead - This paper uses overhead drone imagery (sub-meter, 10cm Ground Sample Distance), population polygons, Open Street Map (OSM) segmentation masks and convolutional network to estimate refugee camp population. It's a great illustration of using ML and improved sensor capabilities for social good. - Shioulin
July 30, 2020 10:00am PT | 1:00pm ET
What if you could ask your email client, "Who sent me the link with the latest financial report?" Automated question answering is a human-machine interaction to extract information from data using natural language. This general capability can take many forms, but one of the most exciting developments has been question answering from unstructured text data, including the massive amounts of information contained in emails, social media posts, blogs, log files, financial statements - and the list goes on. Thanks to a series of advances in deep learning techniques in the past two years, question answering capabilities have grown rapidly, and while still emerging, it's the perfect time to examine how this technology works, when it works well, and where it might still fall short.
In this webinar, we'll cover
We'll also do a live demonstration of a QA prototype that we built. You won't want to miss it, so we hope to see you there!
To unsubscribe from future emails or to update your email preferences, click here. |

We are pleased to announce that we will soon be releasing an updated edition of our report on Interpretability. In conjuction with the report release, please join us on April 9th for a webinar entitled: Opening the ML Black Box: Deploying Interpretable Models to Business Users. You can register here!
by Keita

This is the first part of a series to review Bias in Knowledge Graphs (KG). We aim to describe methods of identifying bias, measuring its impact, and mitigating that impact. For this part, we'll give a broad overview of this topic.
Knowledge graphs, graphs with built-in ontologies, create unique opportunities for data analytics, machine learning, and data mining. They do this by enhancing data with the power of connections and human knowledge. Microsoft, Google, and Facebook actively use knowledge graphs in their products, and the interest from large and medium enterprises is accelerating. Andrew Reed gives a great overview of knowledge graphs in a previous article.
How are knowledge graphs used? Often they are deployed in the backend of an application, for example, supporting search results or responses from conversational AI. In other cases, knowledge graphs are used more directly to grow a knowledge base by finding or validating new information.
As the usage of this technology ramps up, bias in these systems becomes a problem that can contaminate results, degrading the user experience or driving bad decisions. In the last 1-2 years, interest has grown in identifying and removing bias.
Here are some hypothetical cases where bias in knowledge graphs could raise issues:
Conversational AI: Catherine, a college junior, interacts with a 'career bot', a conversational AI agent that offers job advice to graduating students. A knowledge graph based on the university's record of successful alumni underpins the AI agent. Catherine is a pre-med major with aspirations to become a surgeon. In the school's records, most successful surgeons are male. The conversational AI steers Catherine towards medical fields where there are historically more women.

Search: John is using a search engine to research vaccines. He is a layman with no deep knowledge of this area. The search results include hyperlinks and a sidebar of information and links generated from a large structured data source (based on "Wiki-Encyclopedia"). Wiki-Encyclopedia's article has been curated and updated by many people who have strong - but false - notions about the side-effects and efficacy of vaccines. As a result, when John reviews the search results and sidebar, he comes away with flawed - not well informed - notions about vaccines.
Knowledge Base Building: A hospital is building and expanding a knowledge graph. Part of this process involves algorithmically accepting or rejecting new 'facts' to add to the knowledge graph. If the foundational data is itself biased, it could lead to the machine rejecting legitimate facts that go against the bias of the foundational data.
In general, our work is focused on bias that results in "systematic errors of judgment and decision making" by the consumers of KG & ML applications*.
Bias is a broad topic, which has many context-dependant definitions. Data scientists and statisticians are concerned with bias that is more technical and measurable, while less technical stakeholders may have their own definitions and standards for identifying when bias occurs.
Within the machine learning community, several types of bias have been identified and studied (Mehrabi, et. al. define 23 types of bias relevant to machine learning in a recent paper.)
Aside from the types of bias, there are also places in the stages of an analytical or machine learning pipeline where bias can be identified.
Data. Structured and unstructured data form the raw materials for building knowledge graphs. This data can be crowd-sourced, as with Wikipedia and Amazon's Mechanical Turk, or it can be gathered and curated privately, as with a private corporation's records and transactions.
If data was generated by people with a prevalent opinion (self-selection bias) or from a majority of people of a certain cultural perspective (sometimes called representational or population bias), this can impact the downstream results. An example of self-selection bias is when customers who have strong motivations write service reviews. These may not reflect that majority of customers, but if a knowledge graph is built on top of such data, it may learn a distorted view of customer sentiment.
Semantic/Ontology. Ontologies are a framework of meaning which supports the input data and their relationships. Such frameworks are constructed top-down or bottoms-up, and can be manually designed or formed algorithmically. If built by a team of experts, conscious and representational bias can impact the structure of the ontology. If built by machine, bias in the underlying data can bleed into the ontology.
An example can be found in geographical ontologies. Anthropocentric biases lead designers to over emphasize human-centric locations versus natural ones. The Place branch of the DBpedia ontology (as of 2015), contained "dozens or even hundreds of classes for various sub-classes of restaurants, bars, and music venues, but only a handful of classes for natural features such as rivers" [Jancowicz].
Knowledge Graph Embeddings. Embeddings are lower-dimensional representations that enable more efficient processing of knowledge graph data, which is normally in a high-dimensional, and hard-to-wrangle form. It has recently been shown that social biases in knowledge graphs can get passed on to their respective embeddings [Fisher].
Inferential. Inference refers to when a query, machine learning algorithm, or fact-learning algorithm learns from a knowledge graph, or its embeddings. An oft-mentioned example is that of an inferential algorithm learning that only men can be the US President, because historically that has been the only case.
In the next part of this series, we'll examine in more detail concrete examples of the data and ontology bias, and examine known methods to detect and measure such bias.
J. Fisher, Measuring Social Bias in Knowledge Graph Embeddings, Dec 2019.
K. Janowicz, et. al, Debiasing Knowledge Graphs: Why Female Presidents are not like Female Popes, Oct, 2018.
N. Mehrabi, et. al, A Survey of Bias and Fairness in Machine Learning, Sept 2019.
*Drawing from the definition in the K. Janowicz reference.
We'd like to highlight this article about the regulatory perspective on privacy, data governance, and machine learning by Varun on the Cloudera Fast Forward blog, but here are a few other interesting reads, as well:
A brief primer on the state of research and engineering in Question Answering. If you don't know a ton about question answering, but you've heard all the hype about BERT and the other fancy pre-trained models out there, this is a good (and fast) overview of what things were and what just changed.- Ryan
Ask 10 people what they think are the biggest challenges facing AI and you'll probably get 10 different answers - anything from hurdles to implementation and adoption, to inherent biases exhibited in many of these systems, to their general inability to generalize. But underneath all of these challenges lies another that's arguably more fundamental. This provocative paper critically examines the way that deep learning systems learn and demonstrates that overemphasis of metrics can lead to myriad unintended consequences. - Melanie
Transformer based models (such as BERT) have shown extensive improvements for NLP tasks. This paper provides a concise overview, limitations of BERT and future work directions. - Victor
Solving the labeled data problem using GANS - with DermGAN one can "create synthetic images for pre-specified skin condition while being able to vary its size, location and underlying skin color." - Shioulin
Orca, a unique visual programming language, is fascinating to me. It's great to hear its creator, Devine Lu Linvega, talk through its puzzle-game origins and how the community around it developed. - Grant
This 1983 paper examines the then state of the UNIX programs we know and love, like cat, ls and pr. It is mostly praising the simplicity and modularity of their earlier implementations, and bemoaning the conflated functions that had even then begun to creep in. I am enamoured with the UNIX philosophy of small, sharp tools that do one well-defined thing (and do it well), and I think that philosophy is every bit as relevant almost 40 years on. - Chris
Organizations are continuously expanding their data science and analytics footprint by hiring more and more talent into data-focused roles. With this influx of analytics practitioners comes a need to centralize and share the fruitful data insights that are uncovered. To help ensure insights aren't stuck locally within a team, Spotify has developed library tool - called Lexikon - for cataloguing and exposing data and insights across the organization. - Andrew
This article provides a clear framing for where to look for bias in model development and highlights subtleties regarding how finding fairness is not simply a matter of omitting gender and race data during feature selection. - Brian
A platform which allows you to create and host a blog free of advertisements! ML practitioners often share their modeling results with visualizations, text, raw output numbers and at times with even a bit of a code! That said, not every reader is interested in code. To address this problem, fast.ai and Github have teamed up to release fastpages, a blogging platform (built on Github pages for hosting and powered by nbdev) that enables users to include interactive content including collapsable code cells, data tables, visualizations. With fastpages, users can easily convert a Jupyter notebook, Word document, or Markdown file into a content-rich blog post. It also allows for embedding Twitter cards and Youtube videos. - Nisha
This article explains nicely an emerging practical use of graph neural networks: used as Transformers, they are supplanting RNNs for natural language applications. - Keita
And for a little light reading:
Researcher Janelle Shane writes a humor blog called AI Weirdness, about her misadventures in training neural nets. A couple of weeks ago, she trained a neural net on candle names; last week she trained it on candle descriptions. Some of the descriptions it generated are extremely amusing. - Danielle

To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the August edition of Cloudera Fast Forward's monthly newsletter. Our team have been taking some well-deserved vacation this month, but we have several new research projects underway that we're excited to share with you soon. In the meantime, several of our recent webinars are available to watch on-demand, and our research engineers have some new recommended reading to share.
What if you could ask your email client, "Who sent me the link with the latest financial report?" Automated question answering is a human-machine interaction to extract information from data using natural language. This general capability can take many forms, but one of the most exciting developments has been question answering from unstructured text data, including the massive amounts of information contained in emails, social media posts, blogs, log files, financial statements - and the list goes on. Thanks to a series of advances in deep learning techniques in the past two years, question answering capabilities have grown rapidly, and while still emerging, it's the perfect time to examine how this technology works, when it works well, and where it might still fall short.
Machine learning allows us to detect subtle correlations in large data sets, and use those correlations to make accurate predictions. However, these subtle correlations are often spurious - they exist only in a particular dataset - and the resultant model performs poorly, or gives unexpected results in the real world. Moreover, reasoning based on spurious correlations is dangerous. Business decisions should be based on things that are true, not things that are true only in a limited dataset. The trouble, of course, is identifying what is spurious and what is not. In this report, we explain how combining causal inference with machine learning can help us address these problems.
Machine learning (ML) techniques like deep learning can deliver transformative business outcomes, yet the black-box nature of these approaches creates barriers of understanding that can slow adoption to a halt. ML model interpretability, or the ability to explain why and how a model makes a prediction, can enable enterprises to quickly understand predictive outcomes and confidently make decisions that optimize for future business results.
Our research engineers share their favourite reads of the month.
Nisha Muktewar will be speaking about our research on Deep Learning for Anomaly Detection at Open Data Science Conference Europe on September 17th.
To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the October edition of Cloudera Fast Forward's monthly newsletter. We're happy to share some our latest research, and invite you to our next webinar: tomorrow!

Time series data is ubiquitous, and forecasting has a long history. Generalized additive models give us a simple, flexible and interpretable means for modeling some kinds of time series, especially where there is seasonality. We look at the benefits and trade-offs of taking a curve-fitting approach to time series, and demonstrate its use via Facebook's Prophet library on a demand forecasting problem.
Our report, Structural Time Series, is freely available online, and accompanied by code applying the techniques discussed to forecasting electricity demand in California.
Within this research cycle, we will be revisiting the topic of semantic search on image data. We explore two critical requirements for semantic search at scale - strategies for creating semantic representations of images (supervised, unsupervised, semi supervised methods) and methods for fast approximate nearest neighbor search (e.g. FAISS). We will also be releasing an update to the well used ConvNet Playground App, and a set of scripts and tutorials for implementing semantic image search on the Cloudera Machine Learning platform.
Our research engineers share their favorite reads of the month.
What makes fake images detectable? Detecting fake images is a constantly evolving problem with a number of ethical considerations. The approach discussed in the paper helps determine whether an image was produced from a camera or doctored from a deep neural network or was partially manipulated. It does so by focussing on textures in the local area in hair, backgrounds, mouths, and eyes, rather than the global semantics of the image. The approach uses a fully-convolutional patch-based classifier to focus on these local patches, and tests on different model resolutions, initialization seeds, network architectures, and image datasets. The idea being that CNNs are sensitive to these textures which makes them well suited for this purpose. While detecting fake images is a cat-and-mouse problem, approaches like these can help practitioners understand where manipulations can occur and better anticipate them. - Nisha
Monitoring and Explainability of Models in Production Monitoring of deployed machine learning models is a critical (and often overlooked) step in the machine learning lifecycle. The authors of this paper outline four important components following model deployment that help ensure the continued success of machine learning services in production: monitoring model performance, monitoring metrics related to incoming data, detecting outliers and data drift, and explaining model predictions. - Andrew
The Visual Display of Quantitative Information I recently re-read Edward Tufte's classic treatise on data viz. I do not agree with everything in the book. Over-optimizing on maximizing the data-ink ratio (which the book encourages) sacrifices understanding, and Tufte presents a "preferred form" of a quartile chart I find absurd. Nonetheless, there is much wisdom within, and while the book may no longer represent the state of the art, very many data graphics would be substantially improved by adopting its edicts. - Chris
How to Use t-SNE Effectively While the UMAP algorithm is quickly becoming ubiquitous for dimensionality reduction and visualization, many applications still use the traditional t-SNE approach. The flexibility of the t-SNE algorithm provides usability, but also complexity. t-SNE figures can be difficult to interpret, sometimes displaying structure that doesn't exist, or masking true relationships as noise. This classic Distill article details best practices for using t-SNE through a series of gorgeous illustrations on simple datasets, and provides tips on how to develop your t-SNE intuition. - Melanie
Making Sandspiel I've been working on learning WebGL and I've myself returning often to Max Bittker's write-up on how he made the web-based falling sand game Sandspiel. Sandspiel is wonderful in its own right, but what I love about the write-up is that it's a pragmatic and human account of building an application that incorporates some pretty cutting-edge web technologies (Rust compiled to WebAssembly for particle simulation and WebGL shaders for fluid simulation). I think it captures the process of prototyping something, where you're perpetually experimenting and adjusting, really well. - Grant
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey Self-supervised and unsupervised learning methods allow us train models without the costs associated with data annotation. This extensive review covers the motivations, general pipelines and methods that have been used for self-supervised visual feature learning. I find the treatment on strategies used to construct **pretext tasks particularly useful. These strategies can be adapted in deriving semantic representations for multiple data domains beyond images e.g. system logs, network traffic sequences, multimodal text and image data, tabular data. **Pretext tasks are (mostly artificial) tasks designed for a neural network to solve that results in learning useful representations. - Victor
Our first ever Research Roundup webinar is tomorrow! Join us to hear about our two recent releases: meta-learning, and structural time series. If you can't make it, catch up on-demand later!
To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the December edition of Cloudera Fast Forward's monthly newsletter. We have a bumper pack of releases for the holiday season: a new research release, the open sourcing of three previous reports, and, as usual, our team's recommended reading for the month.
Text classification is a ubiquitous capability with a wealth of use cases including sentiment analysis, topic assignment, document identification, article recommendation, and more. But collecting enough annotated examples to train traditional classifiers can be quite costly. Instead, we take a look at a classic technique that can be used to perform text classification with few or even zero training examples! We're talking about text embeddings, of course. New advances have significantly increased the quality of document embeddings and in our newest writing on Few Shot Text Classification this cycle we cover
Follow the links in the report to find code snippets so you can try it for yourself, and build your own demo so you can see the method in action!

Two years ago we wrote a research report about Federated Learning. We're pleased to make the report available to everyone, for free. You can read it online here: Federated Learning.
In the time since, it has only grown in relevance. Numerous startups have cropped up (and some disappeared by acquisition) with Federated Learning as their core technology. Google continues to promote the technology, including for non-machine learning use cases, as in Federated Analytics: Collaborative Data Science without Data Collection. This year saw (what we believe to be) the first conferences with a heavy focus on federated learning, The Federated Learning Conference and the Open Mined Privacy Conference, as well as dedicated workshops at high profile machine learning conferences like ICML and NeurIPS.
OpenMined continues to build a strong community around private machine learning, creating courses and open source tools to lower the barrier-to-entry to federated learning and related privacy enhancing techniques. Alongside those, TensorFlow Federated, IBM's federated learning library and flower.dev are extending the tooling ecosystem.
Federated Learning is no panacea. In a privacy setting, decentralized data simply presents a different attack surface to centralized data. Not all applications require or benefit from federation. However, it is an important tool in the private machine learning toolkit.
To accompany last month's research on Semantic Image Search (checkout the associated blog post Representation Learning 101 for Software Engineers), we're opening up some more previous reports:
Our research engineers share their favorite reads of the month.
To unsubscribe from future emails or to update your email preferences, click here. |

Hello! In this month's edition of our newsletter, we share some thoughts on Enterprise Grade ML, a list of articles and papers we've enjoyed reading, and announcements about our new research efforts. Enjoy!
by Shioulin
At Cloudera Fast Forward, one of the mechanisms we use to tightly couple machine learning research with application is through application development projects for both internal and external clients. The problems we tackle in these projects are wide ranging and cut across various industries; the end goal is a production system that translates data into business impact.
Enterprise grade ML, a term mentioned in a paper put forth by Microsoft, refers to ML applications where there is a high level of scrutiny for data handling, model fairness, user privacy, and debuggability. While toy problems that data scientists solve on laptops using a csv dataset could be intellectually challenging, they are not enterprise grade machine learning problems.
In many of our projects, the most difficult portion is understanding the business problem and defining a mathematical version that can be solved with the data that is available. Sometimes this mathematical version is not what the business stakeholders imagined it to be - this version might only partially solve the original business problem due to data realities. Very often, the business problem is broken down into smaller subproblems. The output of these subproblems then feed into a thin layer of business logic/rules to arrive at a final model output.
Once the problem is clearly defined, and data is flowing properly into the modeling environment, building a model is rather straightforward. When model building becomes convoluted, it can be taken as an indicator of an incorrect problem formulation. There are various ways to approach model building (feature creation, model selection, experimentation) ranging from fully custom approaches to highly automated processes. We are partial to the old-school Python-leveraging-packages approach but can envision the usefulness of AutoML if a data scientist has strong intuition about the business problem and solid understanding of the dataset.
In deployment (via containers or spark applications, for example), governance becomes paramount, especially in regulated environments. Data lineage, data versioning, model versioning, model explainability, model monitoring are all front and center.
Today, we very often need to stitch together ad hoc tools to accomplish all the above. What does the future look like? A recent paper outlines a 10-year prediction for enterprise-grade ML. Along the lines of Software 2.0, the authors view ML models as software derived from data. Most of us in the ML space would agree with this view, and would also acknowledge that even though ML is software, in today's practice we don't yet (always) adopt known best practices in software development.
The authors look to the future from three perspectives: i) model development/training ii) model scoring and iii) model management/governance.
](https://images.registercheck.com/email/0-76f2f8db-fd004d07bb.png)
On model development/training, they believe training and development work will move to the cloud, either private or public. This is consistent with our observations.
On governance, the authors believe that all data, including deployed models (to be thought of as derived data) and inferences made using them will need to be robustly governed. This is something we attempt to do in our current projects - capture code that trained the model, training data that went into it, model inference results - albeit in an ad hoc/brittle way, depending on existing architecture.
The most interesting viewpoint (to me) is their perspective on model scoring. Because machine learning models are software artifacts derived from data, the dual nature of software artifacts and derived data suggests that the boundary between the data world and the modeling world will be fuzzy. The authors believe that inference pipelines will be close to data, and inference on data stored in a database management system should be done as an extension of the query runtime. In other words, models should be represented as first-class data types in a database management system. To investigate this, they "integrated ONNX Runtime (a performance-focused inference engine for ONNX) within SQL server and developed an in-database cross-optimizer between SQL and ML to enable optimizations across hybrid relational and ML expressions." Early results indicate that in-database management system inference is very promising.
As ML adoption quickens within enterprises and ML drives many business decisions, the attention will shift to effects of these models. To reach a state where ML models are defensible (privacy, security, interpretability, speed) without much technical debt, the DB community and the ML community will both shape the future of these ML end-to-end pipelines.
An esoteric title for the layperson, but the results of this paper have heavy implications for the users of graph embeddings. The authors prove that such embeddings fail to capture significant properties of their originating graphs. If embeddings lose key information, this can call into question the downstream results (e.g., machine learning models) that use those embeddings. Such implications are very relevant to my current work in biased knowledge graphs, where embeddings are used in many use cases. - Keita
Everyone and their dog is giving out remote working tips at the moment. This is how Basecamp - a remote and asynchronous company - communicate. The guide is short and authoritative, and you should read it. - Chris
This is a beautiful paper intersecting causality and machine learning. I've spent quite some time with it while preparing our next research release (spoiler alert). For those with a machine learning background who are mystified by causal inference, this is a great starting point on the path, making the connection between causality, invariance, and generalization. - Chris
An amazing post by StitchFix on how they approach data science within their organization through an interactive visualization! StitchFix's take on organizational structure, roles and processes that are unique to them, yet applicable at other companies. And in many ways echoes Cloudera Fast Forward's thoughts in this space. - Nisha
Transformer models have become the golden standard in sequence transduction tasks. This blog post visually depicts the inner workings of a Transformer architecture in a digestible level of detail and explains how this architecture lends itself to efficient, parallel computing. - Andrew
Medication errors happen more often than we'd like to think and its not always the fault of the prescribing doctor or nurse. Most medical systems only have very simple rules-based error alerts for flagging medication issues. In this article, researchers discuss how they are using more sophisticated ML approaches, which are starting to learn how and when a doctor might prescribe a certain medication. This is an important step towards recognizing abnormal prescriptions and potentially saving lives. - Melanie
When we learn the meaning of a new verb "bah," we can easily generate and understand new phrases such as "bah twice." This is not true for neural networks, as they don't quite have the ability to exploit algebraic compositionality. Lake et al construct a simple dataset to test this hypothesis on various RNNs in a controlled manner. The dataset maps commands in words (jump left) into action sequences (LTURN JUMP). The learner's goal is to translate commands into a sequence of actions. The authors find that RNNs can make successful zero-shot generalizations when the difference between training and test commands are small, but fail spectacularly when the link between training and testing data is dependent on the ability to extract systematic rules (as in the "bah" example above). - Shioulin
Towards the beginning of April, we hosted a webinar on interpretability entitled Opening the ML Black Box: Deploying Interpretable Models to Business Users. You can catch the replay here!
We also re-released our previous research on Interpretability (with a few updates) to the public.

Machine learning allows us to detect subtle correlations in large data sets, and use those correlations to make accurate predictions. However, these subtle correlations are often spurious - they exist only in a particular dataset - and the resultant model performs poorly, or gives unexpected results in the real world.
Reasoning based on spurious correlations is dangerous. Business decisions should be based on things that are true, not things that are true only in a limited dataset. The trouble, of course, is identifying what is spurious and what is not.
Join us on May 28th at 10:00am PT / 1:00pm ET for a webinar on Causality for Machine Learning. During the webinar, we'll explain how combining causal inference with machine learning can help us address these problems. We'll cover:
when you should think about causality and lessons to apply in your data science practice
the latest research at the intersection of machine learning and causality
how causal thinking helps us write models that generalize to new circumstances, including an example of the causal approach applied to a computer vision problem
We'll also discuss the ethical implications of causality. We look forward to seeing you there!
Typically, our applied research culminates in a series of comprehensive reports provided to our customers on a quarterly basis, along with a live webinar demonstrating the prototypes we build in conjunction with that research. But times they are a-changin' and we're experimenting with new formats for distributing our content! This time, instead of waiting until the prototype is finished and the report is polished, we thought it would be fun to invite you to join us while we build.
We've launched a blog to host this endeavor at qa.fastforwardlabs.com. Learn more here, and follow us on Twitter for updates on when new content is posted!
For enterprises, getting machine learning (ML) models to production and scale has been a significant challenge. Today, only an estimated 12% of ML models make it to production. To tackle this challenge, Cloudera has released Cloudera Machine Learning (CML) MLOps - a comprehensive and secure production ML platform, built on a 100% open-source standard and fully integrated with Cloudera Data Platform. CML breaks the walls to production and enables end-to-end ML workflows at scale.
Join this webinar on May 6th at 10:00am PT / 1:00pm ET to:
Learn how CML's MLOps functionality eliminates the model 'black box' and drives secure, transparent ML workflows from data to experimentation to production at scale.
Experience CML's robust and flexible model monitoring service for both technical metrics (latency, throughput, etc.) and the mathematical/functional monitoring - including first-class prediction tracking, metric stores, and Python SDK.
See how CML's unique model cataloging and model lineage capabilities eliminate silos and lead to better, faster results.
You can register here.
To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the September edition of Cloudera Fast Forward's monthly newsletter. This month, we're happy to share some new research! This is the first example of a new research format we're experimenting with: more focussed and more frequent. Let us know what you think!

In contrast to how humans learn, deep learning algorithms need vast amounts of data and compute and may yet struggle to generalize. Humans are successful in adapting quickly because they leverage their knowledge acquired from prior experience when faced with new problems. In this report we will explain how meta-learning can leverage previous knowledge acquired from data to solve novel tasks quickly and more efficiently during test time.
Our report, Meta-Learning is freely available online, and accompanied by code that applies the technique to an image dataset.
Our next research release is coming to your screens in October, and will examine the application of generalized additive models to time series problems using the excellent Prophet package.
Our research engineers share their favourite reads of the month.
Funnel Transformer One of the rather active areas of NLP research focuses on how to harness the superior performance of transformer models but at a fraction of the computation costs. The Funnel Transformer takes a step in this direction by introducing an architecture which borrows ideas from CNNs. It uses pooling to gradually compresses the sequence of hidden states in the decoder, leading overall less FLOPs. The authors demonstrate comparable performance to much larger BERT models. - Victor 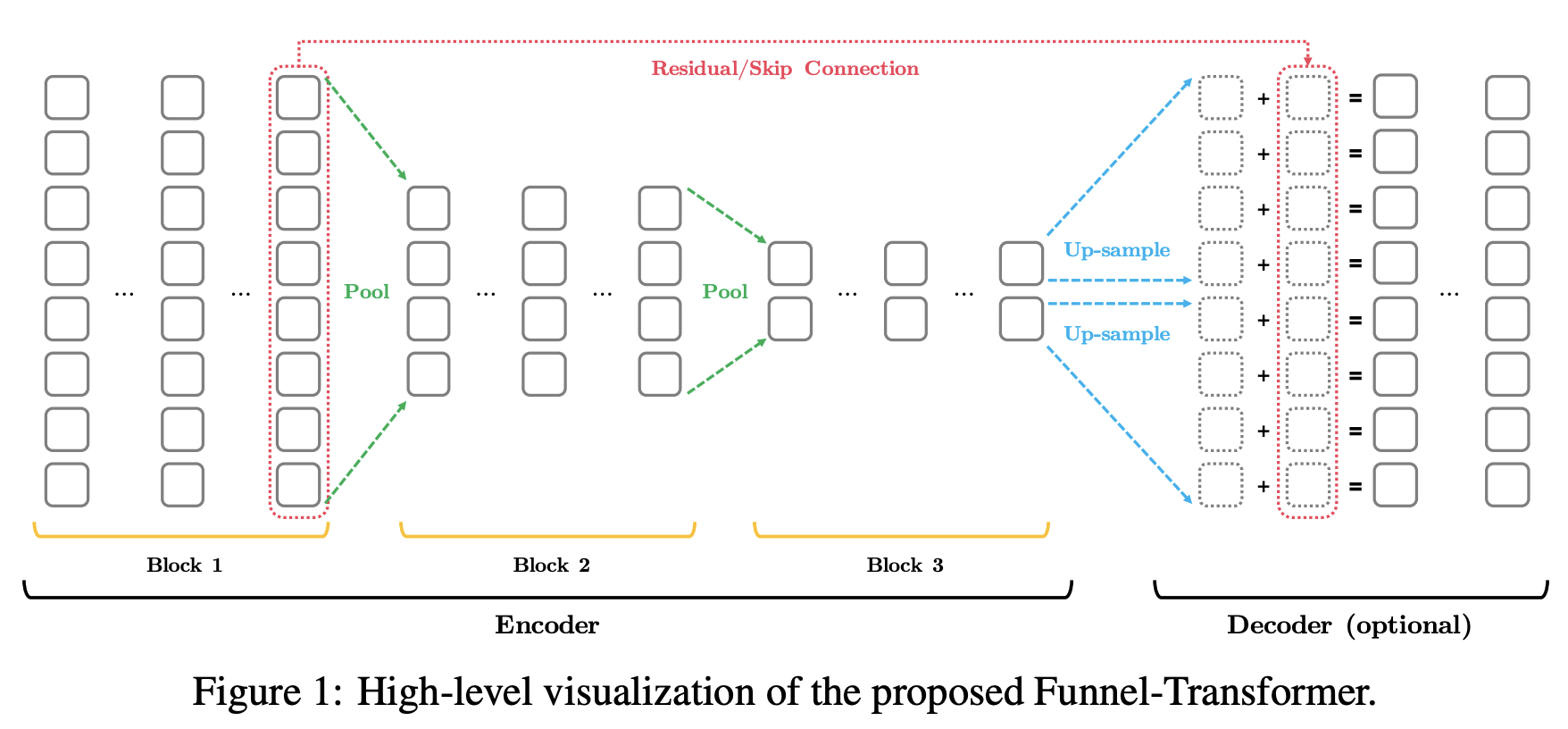
Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case The transformer architecture has taken NLP by storm, so it is unsurprising to see an application to other sequential data. This paper compares a novel transformer architecture for time series forecasting against common time series methods and the state of the art influenza-like illness forecasting model. It finds that the transformer model performs similarly to state of the art. I strongly suspect this is not the last application of transformer models to time series problems we'll see. - Chris
The Language Interpretability Tool: Extensible, Interactive Visualizations and Analysis for NLP Models Another contribution towards interpretable ML, the authors present the Language Interpretability Tool (LIT). LIT is designed to provide visibility and understanding to complex NLP models and tasks. With a minimal amount of code, you can create an interactive, browser-based interface and probe your NLP model with techniques like local explanations, aggregate analysis, and counterfactual generation. It's framework agnostic so it doesn't matter if your models are in Tensorflow, PyTorch, or something else. I'm going to try this out on my NLP workflows and I'll let you know how it goes! - Melanie
MLOps: Continuous delivery and automation pipelines in machine learning
The main hurdle to realizing benefits from a machine learning solution isn't model training. Rather, the actual challenge is building an integrated system that can continuously operate in production. This well developed article by Google discusses best practices for Machine Learning Operations (MLOps) - the engineering culture and process that aims to unify ML system development and ML system operations through the application of standard DevOps principles. By advocating for automation and monitoring at all steps of ML system construction, teams can achieve sustainable ML solutions. - Andrew
Learning to summarize with human feedback
Language models are great, but many are very large. This paper looks into leveraging reinforcement learning and human feedback to train language models that are not only smaller, but also better at summarization. Per the blog post: "Our core method consists of four steps: training an initial summarization model, assembling a dataset of human comparisons between summaries, training a reward model to predict the human-preferred summary, and then fine-tuning our summarization models with RL to get a high reward." The approach is super interesting, and conceptually reminds me of active learning! - Shioulin
To unsubscribe from future emails or to update your email preferences, click here. |

Welcome to the June edition of Cloudera Fast Forward's monthly newsletter. This month, alongside our regular recommended reading, we have two exciting research announcements!
Here in the Fast Forward lab, we're always asking ourselves a lot of questions. Now we're asking BERT a lot of questions too! Our current research focus is question answering systems. In place of a report with all our learnings at the end of our research, we're inviting you to follow along as we explore building a question answering system using modern neural architectures. We just released our third blog in the series, and you can check out each of them below:
Intro to Automated Question Answering
This introductory post discusses what QA is and isn't, where this technology is being employed, and what techniques are used to accomplish this natural language task.
Building a QA System with BERT on Wikipedia
Follow along with this post to build a working Information Retrieval-based QA system, with BERT as the document reader and Wikipedia's search engine as the document retriever. This is a fun toy model that hints at potential real-world use cases.
Evaluating QA: Metrics, Predictions, and the Null Response
In this post, we look at how to assess the quality of a BERT-like model for Question Answering. We cover what metrics are used to quantify quality, how to evaluate your model using the Hugging Face framework, and the importance of the "null response" - questions that don't have answers - for both improved performance and more realistic QA output.
Our latest research report - Causality for Machine Learning - is live, and the webinar is available on demand!
Causality is an emerging area of focus in data science practice, especially when we want to make decisions based on our models. Causality provides a framework for understanding which statistical relationships are true, and which only appear to be true in some circumstances. Our report provides guidance on when and how we need to think about causality.
Even when a problem does not require causal reasoning, we can greatly improve the robustness and generalizability of our machine learning models by taking some lessons from causality. The report outlines techniques that enable machine learning models to perform well across diverse unseen environments, including those that they were not trained on. This is applicable to any machine learning problem where we would like our models to perform well across diverse environments. In particular there are applications in natural language processing and computer vision, which we demonstrate in the accompanying prototype, Scene.
The frontier of simulation based inference Deep learning gets a lot of attention, but it is not the only area of machine learning where progress has been made. Performing inference over intractable likelihoods is widely applicable, and especially where a sophisticated simulator already exists. Examples discussed focus mostly on physical phenomena, from particle colliders, to the structure of the Universe, to epidemics. Personally, I suspect that useful simulators could be constructed for many applied and industrial use cases. This paper outlines recent developments that are enabling statistical inference over these highly complex simulators. - Chris
The Neural Hype and Comparisons Against Weak Baselines This paper illustrates how the use of weak baselines can artificially inflate the "value" of neural methods in the information retrieval domain. In a particularly interesting example, the authors demonstrate how a well designed query expansion approach (BM25 + RM3) provide comparable performance to neural retrieval methods at a fraction of the cost and complexity. - Victor
A Survey of Methods for Model Compression in NLP Transformer-based language models have dramatically advanced the performance of several NLP capabilities like machine translation, summarization, and question answering. However, these models are huge and computationally complex, and implementing them in practice remains challenging with traditional computational constraints. This post summarizes several avenues of research that aim to reduce the size of these beastly models without sacrificing the quality of their output - from software efficiency tricks to techniques like knowledge distillation - making them smaller, lighter, faster and, ultimately, more accessible for practical applications. - Melanie
Shortcut Learning in Deep Neural Networks While the era of deep learning has brought about significant progress and advancement in the field of machine intelligence, a general focus on shattering traditional performance benchmarks has overshadowed the due diligence needed to truly understand model limitations. This paper discusses shortcut learning - the idea that deep learning models often learn superficial rules to perform well on a given benchmark and consequently fail to transfer that level of performance to real-world scenarios. The authors present a set of recommendations for proper model interpretation and performance benchmarking. - Andrew
StereoSet: Measuring stereotypical bias in pretrained language models This paper releases a thoughtfully crowdsourced dataset along with an evaluation metric (ICAT) to measure biases in four domains: race, gender, religion and professions. The authors tested various pretrained models including BERT, RoBERTA, XLNet, GPT2. They show, not surprisingly, that these models exhibit strong stereotypical biases from both a within-sentence and intra-sentence perspective. Dataset and leaderboard can be found at https://www3.cloudera.com/e/593381/2020-06-25/2gh44mv/946606541?h=LlwkEwx_SgYaSwtTsxukwh9N-uEuEGnOi1XD0C7d2Ik - Shioulin
Designing and evaluating metrics Our ability to capture data and measure outcomes enables us to improve our products, decisions, user experience and such. And while this is increasingly applicable in the data science world, it's been how scientific pursuits have been long accomplished. This blogpost by Sean Taylor discusses five main properties to keep in mind when designing a metric: cost, simplicity, faithfulness (which is often invalidated due to sampling bias or by measuring the wrong thing), precision and causal proximity (that measures how closely your product or decision changes affect the metric). Further, he discusses how metric design is an iterative process that requires input from multiple stakeholders and like code involves testing, re-evaluation, tweaking and could be eventually replaced. - Nisha
To unsubscribe from future emails or to update your email preferences, click here. |

Hello! We are pleased to announce the official launch of our latest report on Deep Learning for Anomaly Detection! This report is free to the public, and available for download here.

If you missed the webinar introducing the report, you can catch the replay on demand anytime.
Last month, we introduced you to one of our latest experiments, Anomagram. This month, we introduce our newest prototype, Blip. Blip shows how four different algorithms (Principal Component Analysis, One Class Support Vector Machine, Autoencoder, Bidirectional GAN) perform at detecting network attacks in the KDD network intrusion dataset. You can read about how each model was trained in the prototype section of our report.
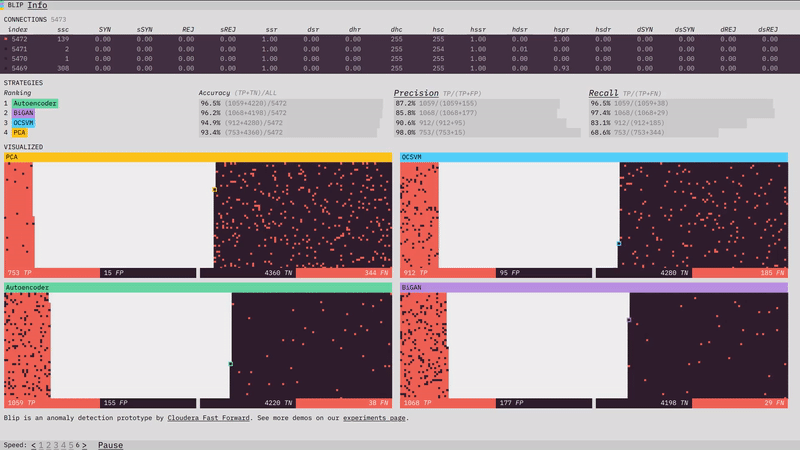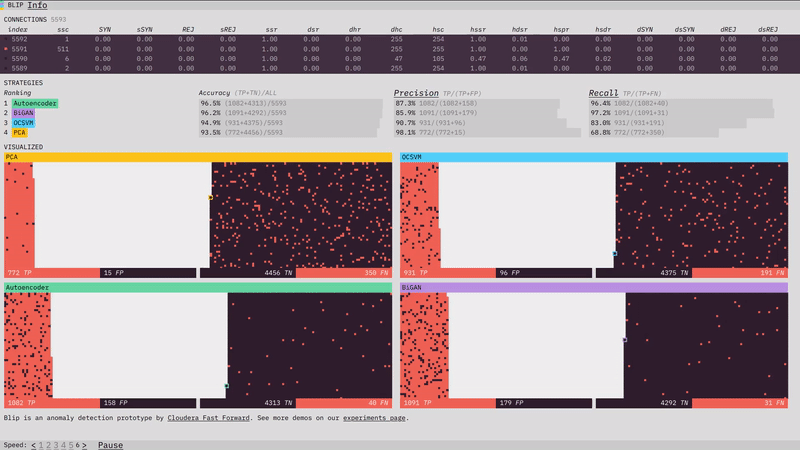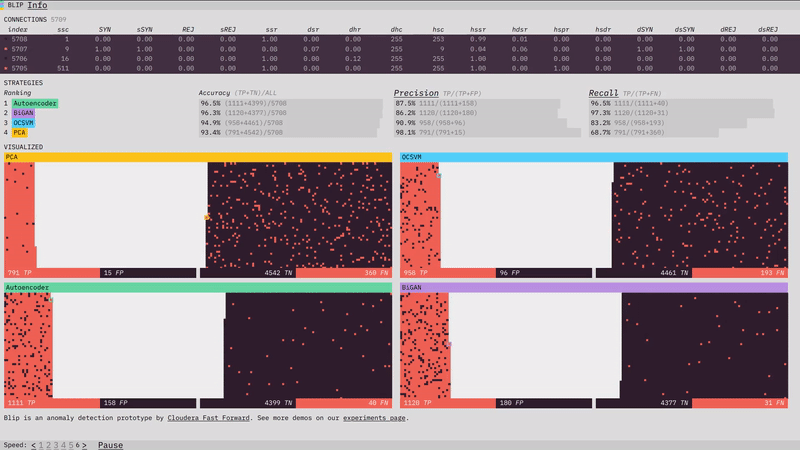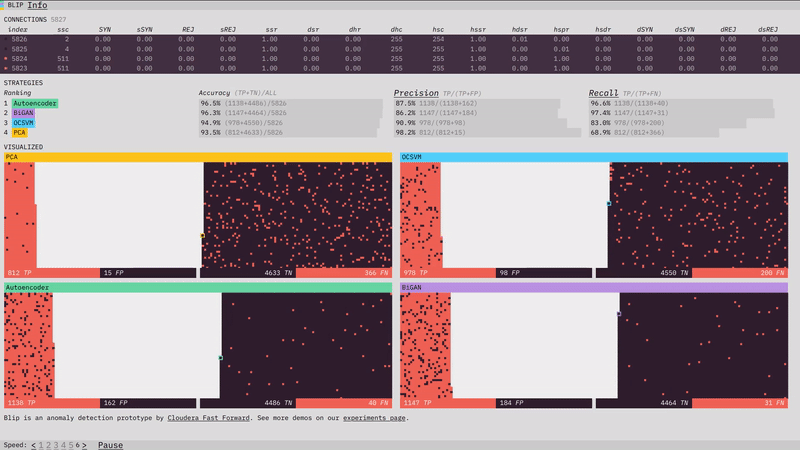
For this month's recommended reading list, we've branched out a bit into podcasts, talks, and videos - as well as our usual collection of articles and libraries. Enjoy!
Capitalizing on ML requires deployment. This article outlines strategies for deploying ML models that utilize embeddings such as recommender or search systems. These are more challenging because model updates necessarily mean recalculating all the associated embeddings. The authors outline both static and streaming strategies for how to structure this production problem and minimize downtime between model upgrades. - Melanie
The machine learning library that underlies spaCy has come of age. There's a lot to love: type annotations, a composable, functional API, interop with PyTorch, TensorFlow and MXNet and even experimental Jax support. In particular the functional nature appeals to my programming preferences, so I'm hoping to spend some time exploring the library. - Chris
This article highlights some seemingly obvious, yet often ignored, best practices for efficiently executing a machine learning project that I found very relatable. The main takeaways for me were the "10 second rule," rushing to success, and the importance of a good validation set upfront! - Andrew
A quick, but informative blog post that summarizes the key take away's from Google Brain's recently released neural conversational model paper. The paper introduces Meena - a 2.6B parameter end-to-end open-domain chatbot, as well as a new human evaluation metric for chatbots called Sensibleness and Specificity Average (SSA) that has allowed Google to take a strong step in the right direction towards truly versatile and human-like chatbot interaction. - Andrew
I first heard about TrailGuard AI on a podcast this week. It's an Intel project that's having significant impact in elephant conservation, and looking into it sent me down a really fun and educational rabbit trail. The NPR program linked in this article (which, among other things, covers another AI conservation solution called EarthRanger and highlights the importance of interpretability) is fascinating, as is this episode of Intel's "Age of AI" video series. I started watching it for the segment on TrailGuard AI, but it goes on to detail other fascinating AI applications, like the work being done by NotCo to affect environmental impact in the food industry, and by Descartes Labs to predict and pre-empt potential famine. Machine learning really does have so much potential to effect positive change in the world. - Danielle
On the Metal is an interview podcast with people who work at the hardware/software interface. The hardware side is not something I know a lot about, so it's fun to get a glimpse at that part of the world, even if a lot of it goes over my head. It's a good reminder that computers are actual physical objects, and have all the limitations that go with that. My favorite episode of the first season was with game developer Jonathan Blow. - Grant
Want to get involved in an open source project but don't know where to begin? Github's Good First Issues feature connects new contributors/ programmers to find open source projects that match their experience and interests. And, yes, it uses deep learning to do so! Contributors often have trouble figuring out which project to be contributing to that is appropriate for their skill-set, and there is always a need for more participants when it comes to open source projects. So it's a win-win situation and impactful for the open source movement! - Nisha
How to configure the Python toolchain on a new laptop seems to change every few months at the moment. But the community seems to have reached a consensus that poetry (rather than pipenv) is what we should use. This blog post explains how to set it up, along with its friends. - Mike
This breezy, non-technical explanation of databases covers some low level issues and the practical architectures you might see in the wild. - Mike
One of those magical StackOverflow questions when someone who can write clearly goes deep on an interesting question. The tl;dr is "it isn't, if you know what you're doing. But if you don't, it could cost you, lots." - Mike
My colleague Grant turned me on to i3, a tiling window manager for Linux a couple of months ago. I tried it as a novelty, but it stuck. It's quick, flexible, and cuts distractions down. Switching over takes a bit of adaptation, but after a week or so, I had muscle memory such that I barely needed a mouse and could fly through workspaces, monitors, and windows. This is a simple intro that covers the basics and has pointers to some of the common customizations that make the transition smooth and demonstrate quickly what's great about i3. - Ryan
Dr. Bilal Mateen's ODI talk on the use of AI in Health, although provocatively titled, thoughtfully considers the importance of setting up the conditions for properly assessing the efficacy of AI and deploying it accordingly. I think the issues he raises will resonate with enterprise-based ML practitioners grappling with questions of good governance, while also trying to help their organizations scale up their deployment of machine learning. - Ade
And of course:
In this blogpost, Grant Custer shares a behind the scenes look at what went into designing Blip.
To unsubscribe from future emails or to update your email preferences, click here. |
| Data Name | Data Type | Options |
|---|---|---|
| Company | ||
| First name | ||
| Last name | ||
| Title | ||
| Middle name | ||
| Yes, I would like to be contacted by Cloudera for newsletters, promotions, events and marketing activities. Please read our privacy and data policy. | ||
| Yes, I consent to my information being shared with Cloudera's solution partners to offer related products and services. Please read our privacy and data policy. |

 Arts and Entertainment
Arts and Entertainment Business and Industry
Business and Industry Computer and Electronics
Computer and Electronics Games
Games Health
Health Internet and Telecom
Internet and Telecom Shopping
Shopping Sports
Sports Travel
Travel More
More